A Technical Walkthrough of Source Code Verification

Transparency, verifiability, and trustlessness are the core values of blockchains and Ethereum especially. We want the smart contracts we are interacting with to be open-source (right?). However you can't be sure if the open-source code you see is actually the one that lives on chain. I can show you a benign code on GitHub etc. and convince you to send your assets to a contract, but in reality it could be a malicious contract that's actually deployed at this address.
This is where source code verification comes in. Source code verification makes sure the human-readable source code you see is the same as the one that was deployed on chain.
A verified contract does not necessarily mean it is safe to interact with it. The verification does not look into what the contract does, but only that it corresponds to this source-code. The source-code itself can be malicious and contain bugs. It is the auditors' and the community's responsibility to verify the code's security.
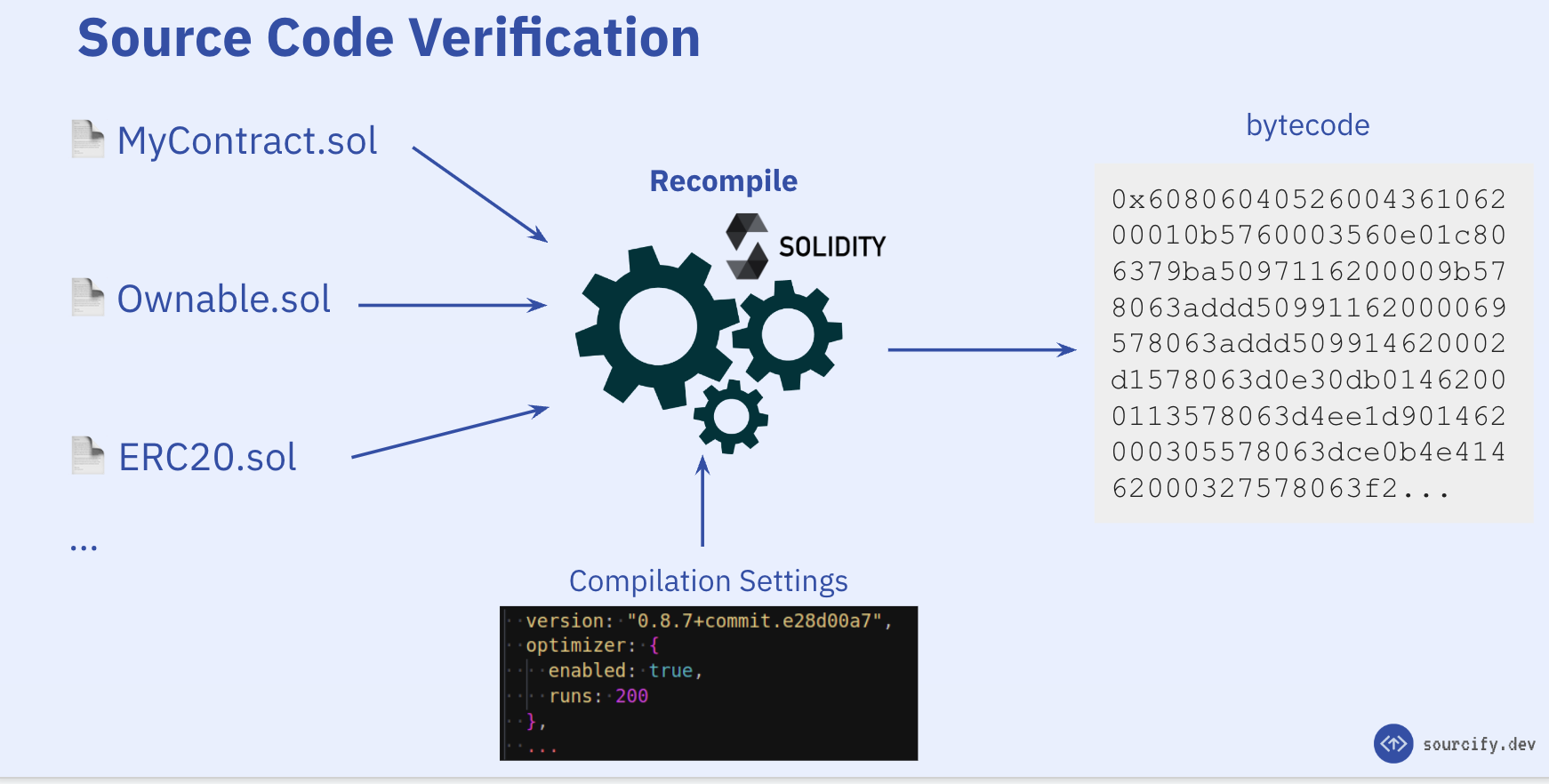
Smart contracts are written in human-readable programming languages like Vyper or Solidity. But they are compiled to and deployed in bytecode (1s and 0s), so they are not human-readable.
0x608060405234801561001057600080fd5b50600436106100365760003560e01c80632e64cec11461003b5780636057361d14610059575b600080fd5b610043610075565b60405161005091906100d9565b60405180910390f35b610073600480360381019061006e919061009d565b61007e565b005b60008054905090565b8060008190555050565b60008135905061009781610103565b92915050565b6000602082840312156100b3576100b26100fe565b5b60006100c184828501610088565b91505092915050565b6100d3816100f4565b82525050565b60006020820190506100ee60008301846100ca565b92915050565b6000819050919050565b600080fd5b61010c816100f4565b811461011757600080fd5b5056fea2646970667358221220404e37f487a89a932dca5e77faaf6ca2de3b991f93d230604b1b8daaef64766264736f6c63430008070033
How a contract looks like on Ethereum - 0x7ecedB5ca848e695ee8aB33cce9Ad1E1fe7865F8 on Ethereum Holesky Testnet
We can go from Solidity/Vyper code to bytecode, but not the other way around. This information is lost during compilation and we need the original source-code that compiles down to this bytecode.
In simple terms, source code verification works by:
- Taking a smart-contract written in a human-readable programming language (Solidity/Vyper)
- Compiling it down to bytecode
- Comparing the compiled bytecode with the on-chain bytecode that is deployed at a certain chain and address.
Of course this is a simplified explanation and there are some nuances to it. In this blog post, we will dive deeper into the technical details of the process and walkthrough how a verification works behind the scenes.
How to Verify?
When you want to verify a contract on Sourcify we need the following:
chainIdwhere the contract is deployedaddressof the contractmetadata.json: The Solidity Contract Metadata file. This JSON file is output by the compiler and contains information about how to interact with this contract (abi, userdoc, devdoc), and how to reproduce the compilation (compilation settings, source hashes or contents)- Source files outlined in the
metadata.json.
Say we wanted to verify the contract 0x48A331150C1b442444F4f0371a4daC9Ab2FC837D on Holesky Testnet.
User request to Sourcify:
{
"address": "0x48A331150C1b442444F4f0371a4daC9Ab2FC837D",
"chainId": "17000", // Ethereum Holesky testnet
"files": {
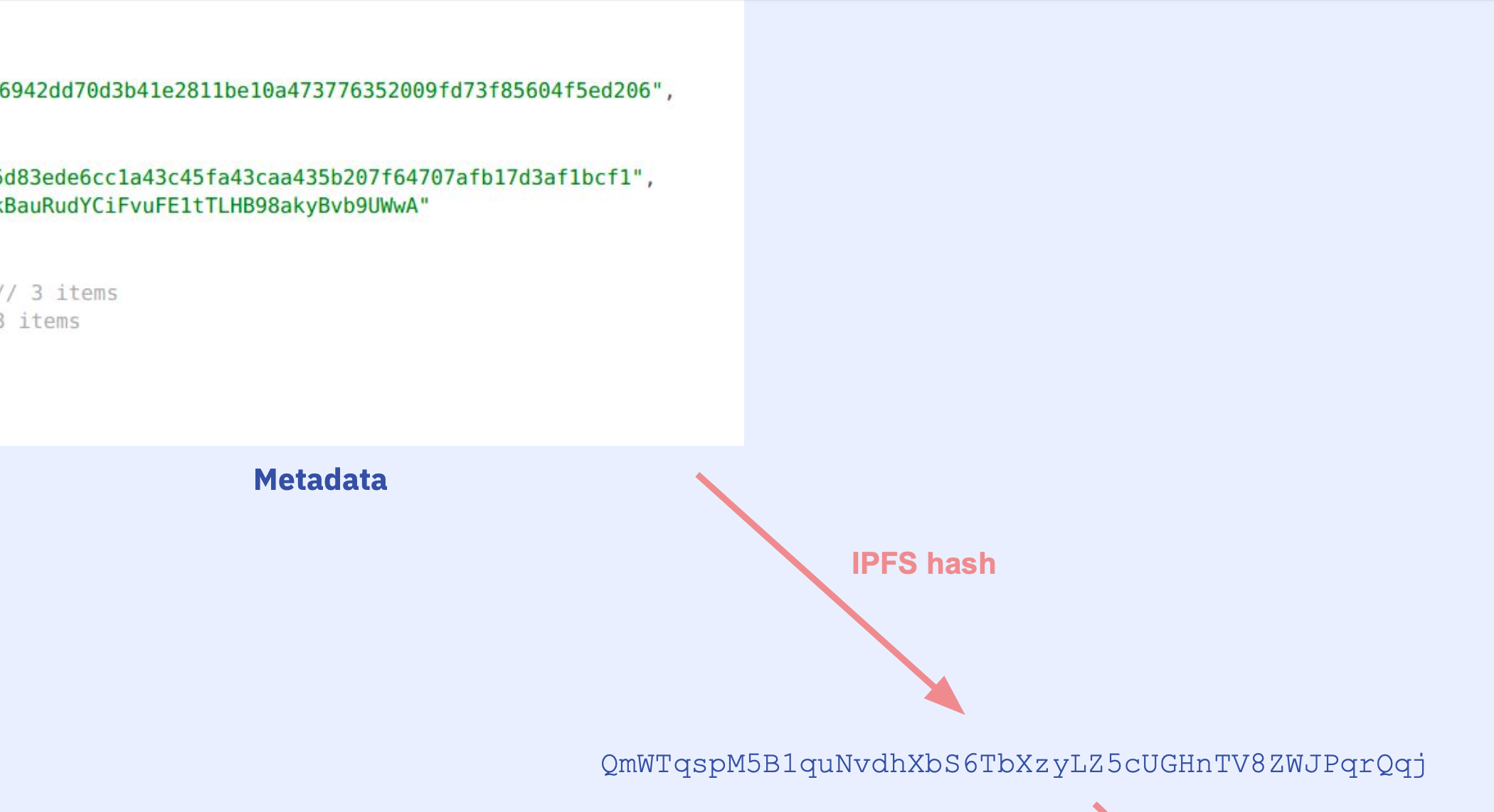
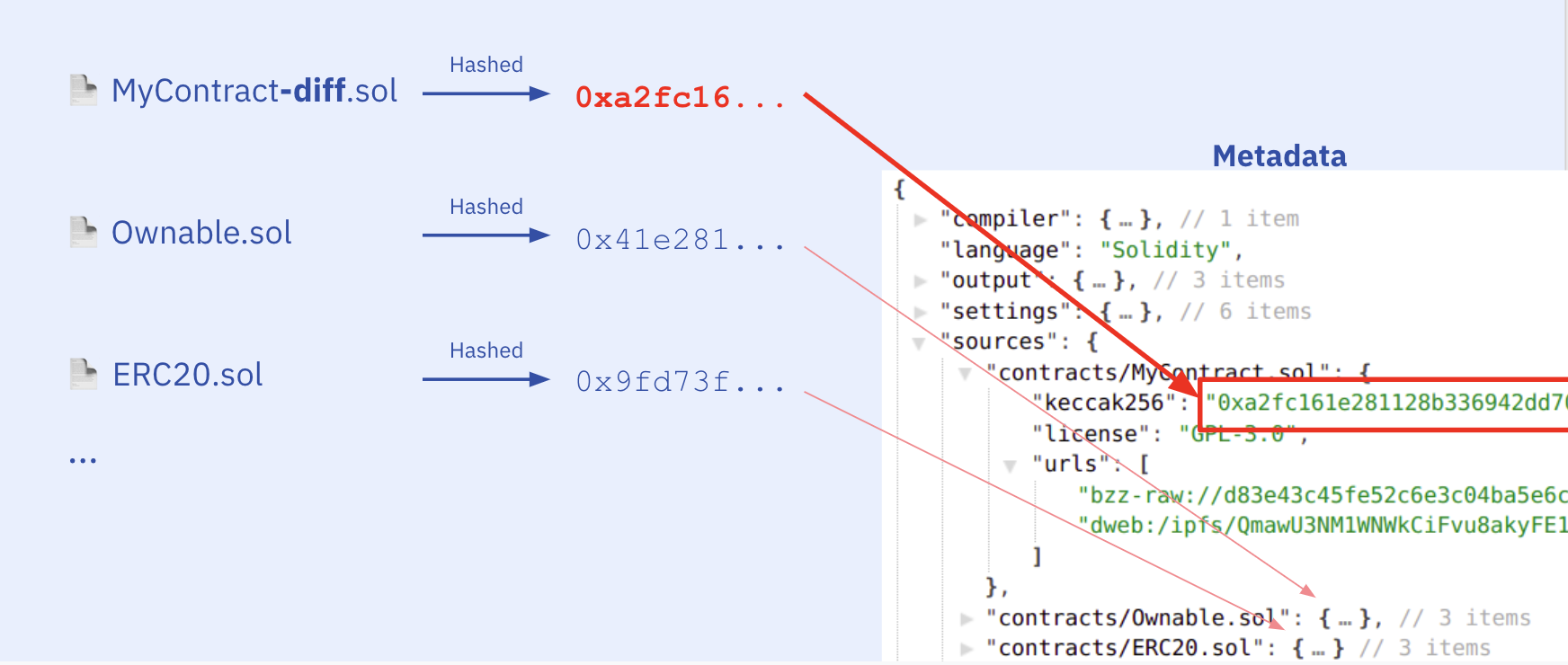
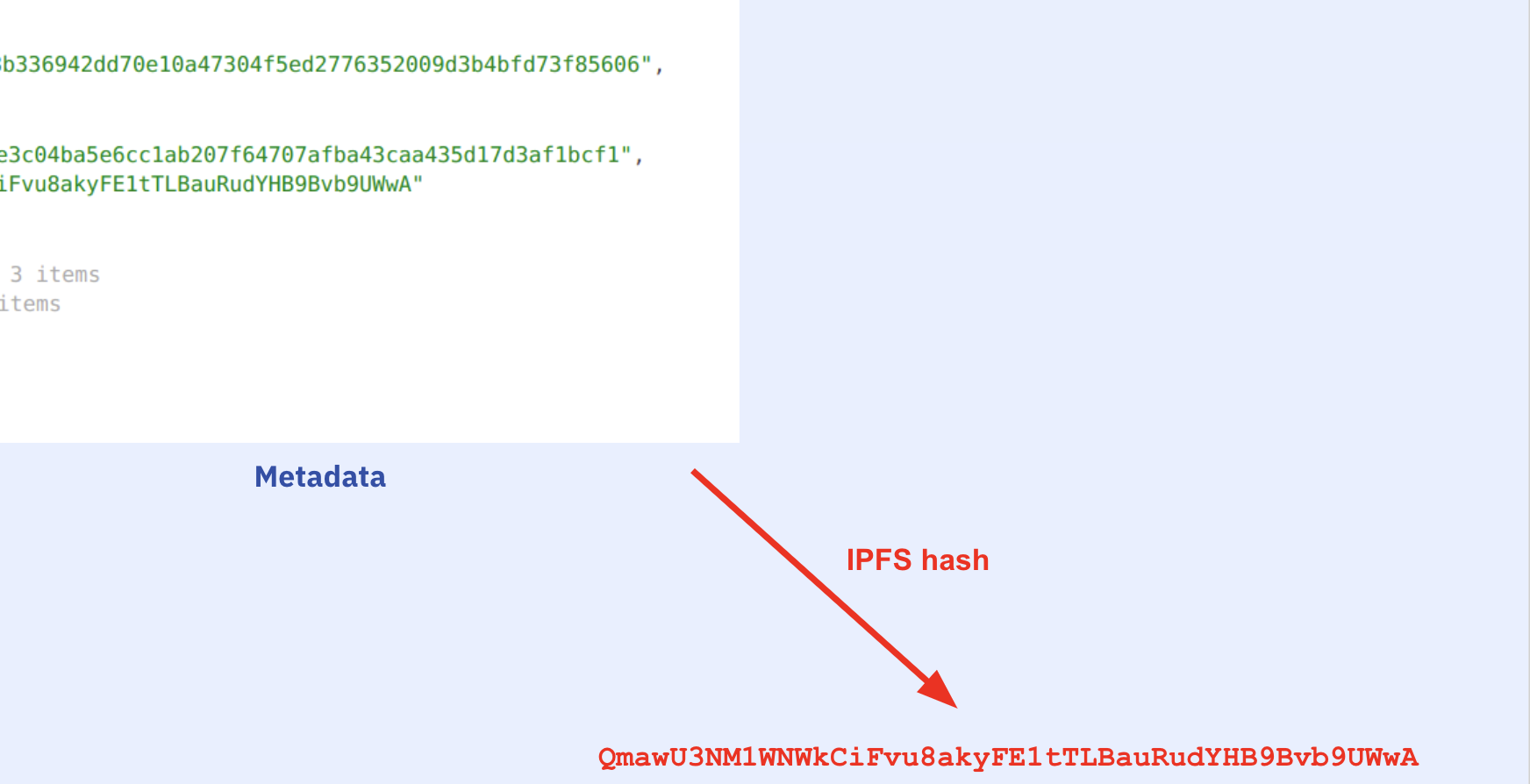
"metadata.json": "{\"compiler\":{\"version\":\"0.8.7+commit.e28d00a7\"},\"language\":\"Solidity\",\"output\":{\"abi\":[{\"inputs\":[],\"name\":\"retrieve\",\"outputs\":[{\"internalType\":\"uint256\",\"name\":\"\",\"type\":\"uint256\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[{\"internalType\":\"uint256\",\"name\":\"num\",\"type\":\"uint256\"}],\"name\":\"store\",\"outputs\":[],\"stateMutability\":\"nonpayable\",\"type\":\"function\"}],\"devdoc\":{\"details\":\"Store & retrieve value in a variable\",\"kind\":\"dev\",\"methods\":{\"retrieve()\":{\"details\":\"Return value \",\"returns\":{\"_0\":\"value of 'number'\"}},\"store(uint256)\":{\"details\":\"Store value in variable\",\"params\":{\"num\":\"value to store\"}}},\"title\":\"Storage\",\"version\":1},\"userdoc\":{\"kind\":\"user\",\"methods\":{},\"version\":1}},\"settings\":{\"compilationTarget\":{\"contracts/1_Storage.sol\":\"Storage\"},\"evmVersion\":\"london\",\"libraries\":{},\"metadata\":{\"bytecodeHash\":\"ipfs\"},\"optimizer\":{\"enabled\":false,\"runs\":200},\"remappings\":[]},\"sources\":{\"contracts/1_Storage.sol\":{\"keccak256\":\"0xb6ee9d528b336942dd70d3b41e2811be10a473776352009fd73f85604f5ed206\",\"license\":\"GPL-3.0\",\"urls\":[\"bzz-raw://fe52c6e3c04ba5d83ede6cc1a43c45fa43caa435b207f64707afb17d3af1bcf1\",\"dweb:/ipfs/QmawU3NM1WNWkBauRudYCiFvuFE1tTLHB98akyBvb9UWwA\"]}},\"version\":1}",
"1_Storage.sol": "// SPDX-License-Identifier: GPL-3.0\n\npragma solidity >=0.7.0 <0.9.0;\n\n/**\n * @title Storage\n * @dev Store & retrieve value in a variable\n */\ncontract Storage {\n\n uint256 number;\n\n /**\n * @dev Store value in variable\n * @param num value to store\n */\n function store(uint256 num) public {\n number = num;\n }\n\n /**\n * @dev Return value \n * @return value of 'number'\n */\n function retrieve() public view returns (uint256){\n return number;\n }\n}"
},
For now the metadata.json is the main way to submit contracts to Sourcify. All other methods such as "Import from Etherscan" all workaround to generate the metadata file in some way, and continue verification from there. This is will change with the Vyper verification and in our APIv2. In Vyper, users will give us a standard JSON and we generate a "fake" metadata.json for backward compatability reasons. In our APIv2 we will no longer use the metadata file as the base of our verification, but the standard JSON as the base.
Example metadata.json file
{
"compiler": { "version": "0.8.7+commit.e28d00a7" },
"language": "Solidity",
"output": {
"abi": [
{
"inputs": [],
"name": "retrieve",
"outputs": [{ "internalType": "uint256", "name": "", "type": "uint256" }],
"stateMutability": "view",
"type": "function"
},
{
"inputs": [{ "internalType": "uint256", "name": "num", "type": "uint256" }],
"name": "store",
"outputs": [],
"stateMutability": "nonpayable",
"type": "function"
}
],
"devdoc": {
"details": "Store & retrieve value in a variable",
"kind": "dev",
"methods": {
"retrieve()": { "details": "Return value ", "returns": { "_0": "value of 'number'" } },
"store(uint256)": { "details": "Store value in variable", "params": { "num": "value to store" } }
},
"title": "Storage",
"version": 1
},
"userdoc": { "kind": "user", "methods": {}, "version": 1 }
},
"settings": {
"compilationTarget": { "contracts/1_Storage.sol": "Storage" },
"evmVersion": "london",
"libraries": {},
"metadata": { "bytecodeHash": "ipfs" },
"optimizer": { "enabled": false, "runs": 200 },
"remappings": []
},
"sources": {
"contracts/1_Storage.sol": {
"keccak256": "0xb6ee9d528b336942dd70d3b41e2811be10a473776352009fd73f85604f5ed206",
"license": "GPL-3.0",
"urls": [
"bzz-raw://fe52c6e3c04ba5d83ede6cc1a43c45fa43caa435b207f64707afb17d3af1bcf1",
"dweb:/ipfs/QmawU3NM1WNWkBauRudYCiFvuFE1tTLHB98akyBvb9UWwA"
]
}
},
"version": 1
}
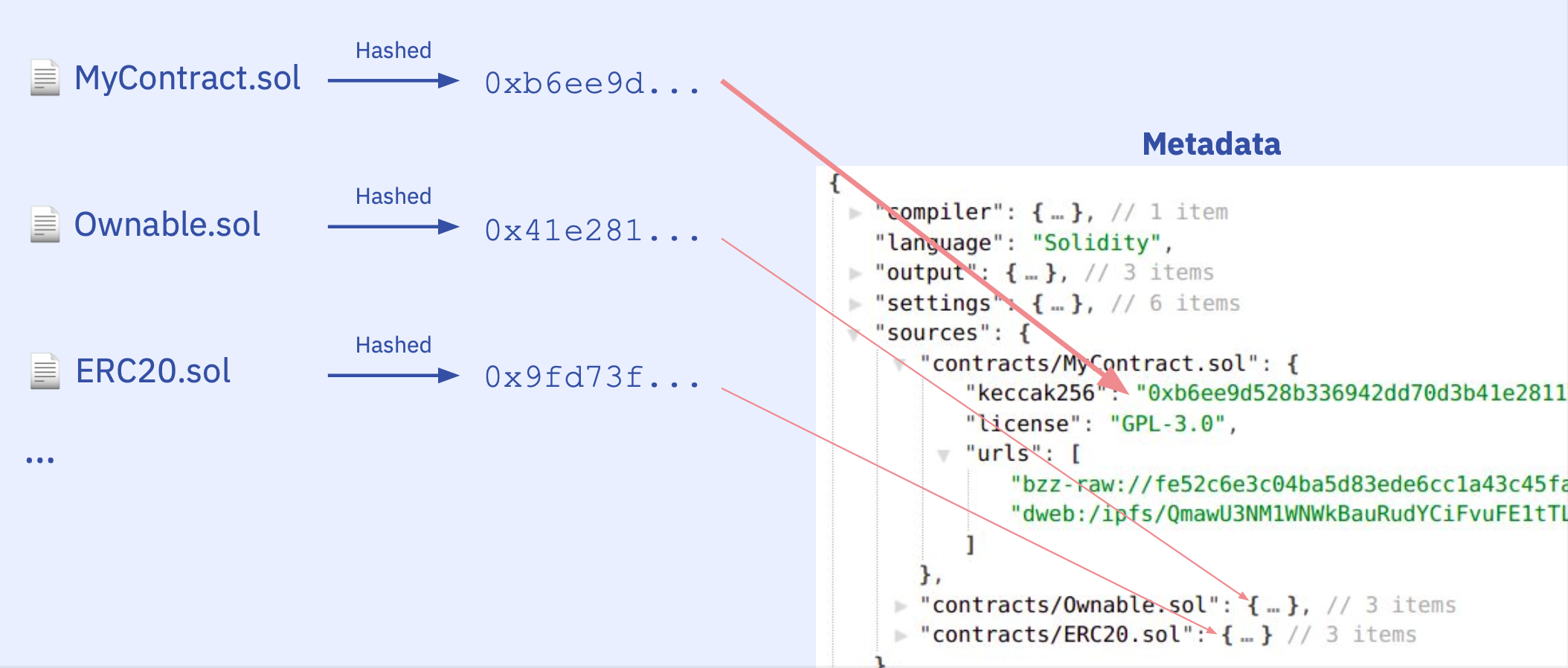
Anyway for now we continue with our metadata.json. To be able to compile we first need to make sure we have everything we need, that are, all the source files and settings outlined in the metadata.json. The JSON file has a sources field that looks like this
"sources": {
"contracts/1_Storage.sol": {
"keccak256": "0xb6ee9d528b336942dd70d3b41e2811be10a473776352009fd73f85604f5ed206",
"license": "GPL-3.0",
"urls": [
"bzz-raw://fe52c6e3c04ba5d83ede6cc1a43c45fa43caa435b207f64707afb17d3af1bcf1",
"dweb:/ipfs/QmawU3NM1WNWkBauRudYCiFvuFE1tTLHB98akyBvb9UWwA"
]
},
...
}
And with the file hashes we can validate the source files user gave us and make sure we have all the source files needed. Taking the user request, we:
- Find the metadata file in the user request
.files(assume the rest are source files) - Hash all other files and keep their keccak
- Additionally generate new line and whitespace variations of the source files to account for the OS and platform differences.
- Try to mark out all entries in
sourcesaccording to theirkeccak256 - If there are sources missing, try to fetch them from their IPFS hash e.g.
dweb:/ipfs/Qmf2J3oWXHBnoNcGXkNYcSirUvJZebXa3j3Cn3vccqS1x7 - If we still have missing sources, tell user what's missing
Assuming we found all the sources we go forward with the compilation with the language, compiler.version and the settings field in the metadata.json:
{
"compiler": {
"version": "0.8.7+commit.e28d00a7"
},
"language": "Solidity",
...
...
"settings": {
"compilationTarget": {
"contracts/1_Storage.sol": "Storage"
},
"evmVersion": "london",
"metadata": {
"bytecodeHash": "ipfs"
},
"optimizer": {
"enabled": false,
"runs": 200
},
},
With this information we create a standard JSON input file and feed it to the compiler.
The compiler will give us an output that looks like this:
{
"contracts": {
"contracts/1_Storage.sol": {
"Storage": {
"abi": [{"inputs":[],"name":"retrieve","outputs":[{"internalType":"uint256","name":"","type":"uint256"}],"stateMutability":"view","type":"function"},{"inputs":[{"internalType":"uint256","name":"num","type":"uint256"}],"name":"store","outputs":[],"stateMutability":"nonpayable","type":"function"}],
"devdoc": {"details":"Store & retrieve value in a variable","kind":"dev","methods":{"retrieve()":{"details":"Return value ","returns":{"_0":"value of 'number'"}},"store(uint256)":{"details":"Store value in variable","params":{"num":"value to store"}}},
"evm": {
"bytecode": {
"generatedSources": [],
"linkReferences": {},
"object": "608060405234801561001057600080fd5b50610150806100206000396000f3fe608060405234801561001057600080fd5b50600436106100365760003560e01c80632e64cec11461003b5780636057361d14610059575b600080fd5b610043610075565b60405161005091906100d9565b60405180910390f35b610073600480360381019061006e919061009d565b61007e565b005b60008054905090565b8060008190555050565b60008135905061009781610103565b92915050565b6000602082840312156100b3576100b26100fe565b5b60006100c184828501610088565b91505092915050565b6100d3816100f4565b82525050565b60006020820190506100ee60008301846100ca565b92915050565b6000819050919050565b600080fd5b61010c816100f4565b811461011757600080fd5b5056fea2646970667358221220404e37f487a89a932dca5e77faaf6ca2de3b991f93d230604b1b8daaef64766264736f6c63430008070033",
"sourceMap": "141:356:0:-:0;;;;;;;;;;;;;;;;;;;"
},
"deployedBytecode": {
"immutableReferences": {},
"linkReferences": {},
"object": "608060405234801561001057600080fd5b50600436106100365760003560e01c80632e64cec11461003b5780636057361d14610059575b600080fd5b610043610075565b60405161005091906100d9565b60405180910390f35b610073600480360381019061006e919061009d565b61007e565b005b60008054905090565b8060008190555050565b60008135905061009781610103565b92915050565b6000602082840312156100b3576100b26100fe565b5b60006100c184828501610088565b91505092915050565b6100d3816100f4565b82525050565b60006020820190506100ee60008301846100ca565b92915050565b6000819050919050565b600080fd5b61010c816100f4565b811461011757600080fd5b5056fea2646970667358221220404e37f487a89a932dca5e77faaf6ca2de3b991f93d230604b1b8daaef64766264736f6c63430008070033",
"sourceMap": "141:356:0:-:0;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;416:79;;;:::i;:::-;;;;;;;:::i;:::-;;;;;;;;271:64;;;;;;;;;;;;;:::i;:::-;;:::i;:::-;;416:79;457:7;482:6;;475:13;;416:79;:::o;271:64::-;325:3;316:6;:12;;;;271:64;:::o;7:139:1:-;53:5;91:6;78:20;69:29;;107:33;134:5;107:33;:::i;:::-;7:139;;;;:::o;152:329::-;211:6;260:2;248:9;239:7;235:23;231:32;228:119;;;266:79;;:::i;:::-;228:119;386:1;411:53;456:7;447:6;436:9;432:22;411:53;:::i;:::-;401:63;;357:117;152:329;;;;:::o;487:118::-;574:24;592:5;574:24;:::i;:::-;569:3;562:37;487:118;;:::o;611:222::-;704:4;742:2;731:9;727:18;719:26;;755:71;823:1;812:9;808:17;799:6;755:71;:::i;:::-;611:222;;;;:::o;920:77::-;957:7;986:5;975:16;;920:77;;;:::o;1126:117::-;1235:1;1232;1225:12;1249:122;1322:24;1340:5;1322:24;:::i;:::-;1315:5;1312:35;1302:63;;1361:1;1358;1351:12;1302:63;1249:122;:::o"
},
"legacyAssembly": {},
"metadata": "{\"compiler\":{\"version\":\"0.8.7+commit.e28d00a7\"},\"language\":\"Solidity\",\"output\":{\"abi\":[{\"inputs\":[],\"name\":\"retrieve\",\"outputs\":[{\"internalType\":\"uint256\",\"name\":\"\",\"type\":\"uint256\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[{\"internalType\":\"uint256\",\"name\":\"num\",\"type\":\"uint256\"}],\"name\":\"store\",\"outputs\":[],\"stateMutability\":\"nonpayable\",\"type\":\"function\"}],\"devdoc\":{\"details\":\"Store & retrieve value in a variable\",\"kind\":\"dev\",\"methods\":{\"retrieve()\":{\"details\":\"Return value \",\"returns\":{\"_0\":\"value of 'number'\"}},\"store(uint256)\":{\"details\":\"Store value in variable\",\"params\":{\"num\":\"value to store\"}}},\"title\":\"Storage\",\"version\":1},\"userdoc\":{\"kind\":\"user\",\"methods\":{},\"version\":1}},\"settings\":{\"compilationTarget\":{\"contracts/1_Storage.sol\":\"Storage\"},\"evmVersion\":\"london\",\"libraries\":{},\"metadata\":{\"bytecodeHash\":\"ipfs\"},\"optimizer\":{\"enabled\":false,\"runs\":200},\"remappings\":[]},\"sources\":{\"contracts/1_Storage.sol\":{\"keccak256\":\"0xb6ee9d528b336942dd70d3b41e2811be10a473776352009fd73f85604f5ed206\",\"license\":\"GPL-3.0\",\"urls\":[\"bzz-raw://fe52c6e3c04ba5d83ede6cc1a43c45fa43caa435b207f64707afb17d3af1bcf1\",\"dweb:/ipfs/QmawU3NM1WNWkBauRudYCiFvuFE1tTLHB98akyBvb9UWwA\"]}},\"version\":1}",
"storageLayout": {
"storage": [
{
"astId": 4,
"contract": "contracts/1_Storage.sol:Storage",
"label": "number",
"offset": 0,
"slot": "0",
"type": "t_uint256"
}
],
"types": { "t_uint256": { "encoding": "inplace", "label": "uint256", "numberOfBytes": "32" } }
},
"userdoc": { "kind": "user", "methods": {}, "version": 1 }
}
},
},
"sources": { "contracts/1_Storage.sol": { "id": 0 } }
}
We are only interested in the compilationTarget (e.g. contracts/1_Storage.sol and Storage) and not all other contracts provided. The two fields of our interest are evm.bytecode.object and evm.deployedBytecode.object.
Onchain vs. Recompiled Bytecodes
Essentially we need to compare some onchain data against a compilation. We will find the onchain bytecodes using the chainId + address provided through an RPC. The recompiled bytecodes will come from the compilation output above.
Onchain vs recompiled refer to where these bytecodes are coming from. Onchain, obviously, comes from a contract that is deployed on a live blockchain. Recompiled, comes from a compilation we perform from source code to obtain bytecodes.
Runtime vs. Creation Bytecodes
We talked about the onchain and recompiled bytecodes. In addition to this, there are also two associated bytecode types to a contract we can perform the verification on.
Runtime bytecode is the bytecode that gets stored at the contract's address and that will be executed when this contract is called.
- The recompiled runtime bytecode is found under
evm.deployedBytecodefield of the compiler outputs. - The onchain runtime bytecode is quite straightforward to get. It can be obtained with
provider.getCode(0xabc..def), essentially with theeth_getCodeRPC call to a node running the chain we are interested in with thechainId.
Creation bytecode or sometimes referred to as the "initcode" is the code that will be executed by the EVM to deploy this contract.
- The recompiled creation bytecode is found under
evm.bytecodefield of the compiler outputs. - The onchain creation bytecode is a little trickier.
- Typically, when a contract is being created by an EOA the receiver of the transaction is set to zero (
tx.to=null), and the creation bytecode is placed in the transaction payload (tx.inputortx.data). The EVM interprets this as a contract creation and executes the transaction payload. - If a contract is created by another contract (factory pattern), we are going to have to look into the transaction traces, ie. every single step within the transaction execution to find the exact place where this contract's creation code was executed. Unfortunately this data is not easily available from RPCs like the runtime bytecode.
- Typically, when a contract is being created by an EOA the receiver of the transaction is set to zero (
To be able to say "Yes this source code is the source code of this contract 0x48A331150C1b442444F4f0371a4daC9Ab2FC837D on Ethereum Holesky Testnet", we will compare the following and try to get a match:
- onchain vs. recompiled runtime bytecodes
- onchain vs. recompiled creation bytecodes
Matching and Transformations
Now we are comparing the bytecodes.
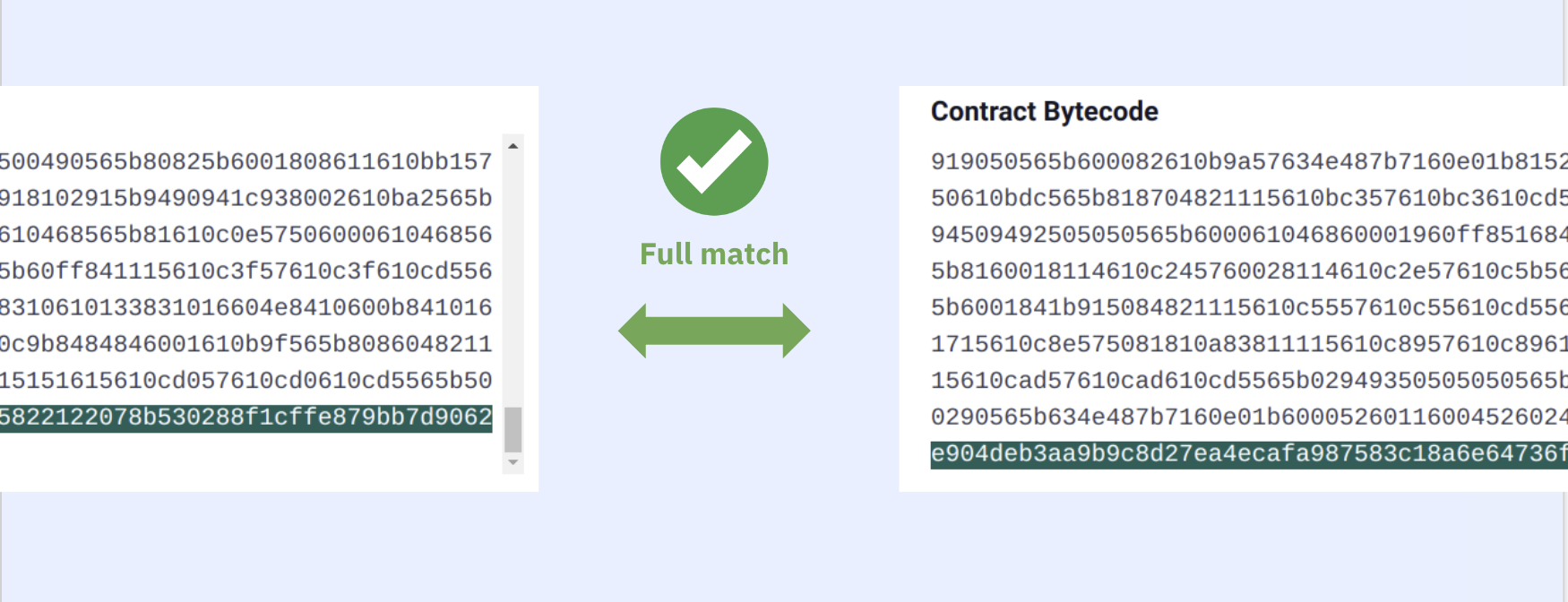
If you're lucky you get a 100% match and you're done. Take this contract:
Storage.sol
// SPDX-License-Identifier: GPL-3.0
pragma solidity >=0.8.2 <0.9.0;
contract Storage {
uint256 number;
function store(uint256 num) public {
number = num;
}
function retrieve() public view returns (uint256){
return number;
}
}
metadata.json
{
"compiler": {
"version": "0.8.26+commit.8a97fa7a"
},
"language": "Solidity",
"output": {
"abi": [
{
"inputs": [
],
"name": "retrieve",
"outputs": [
{
"internalType": "uint256",
"name": "",
"type": "uint256"
}
],
"stateMutability": "view",
"type": "function"
},
{
"inputs": [
{
"internalType": "uint256",
"name": "num",
"type": "uint256"
}
],
"name": "store",
"outputs": [
],
"stateMutability": "nonpayable",
"type": "function"
}
],
"devdoc": {
"kind": "dev",
"methods": {
},
"version": 1
},
"userdoc": {
"kind": "user",
"methods": {
},
"version": 1
}
},
"settings": {
"compilationTarget": {
"contracts/1_Storage.sol": "Storage"
},
"evmVersion": "cancun",
"libraries": {
},
"metadata": {
"bytecodeHash": "ipfs"
},
"optimizer": {
"enabled": false,
"runs": 200
},
"remappings": [
]
},
"sources": {
"contracts/1_Storage.sol": {
"keccak256": "0x37ee358e0c9d3c9a75b75a2723ad8ab652c9e93ca38954426a5e9f8b80b83452",
"license": "GPL-3.0",
"urls": [
"bzz-raw://2c734f79c940178a38088a7803161d0cc793ec51e917ce17fe279739368c0018",
"dweb:/ipfs/QmRsfA8ZQo8TrnSKamMSC3JGAZtuNJhhuadHntY7AjEqew"
]
}
},
"version": 1
}
Deployed at 0x48A331150C1b442444F4f0371a4daC9Ab2FC837D on Holesky Testnet, it has the following bytecodes:
Runtime Bytecodes: Onchain vs. Recompiled:
0x608060405234801561000f575f80fd5b5060043610610034575f3560e01c80632e64cec1146100385780636057361d14610056575b5f80fd5b610040610072565b60405161004d919061009b565b60405180910390f35b610070600480360381019061006b91906100e2565b61007a565b005b5f8054905090565b805f8190555050565b5f819050919050565b61009581610083565b82525050565b5f6020820190506100ae5f83018461008c565b92915050565b5f80fd5b6100c181610083565b81146100cb575f80fd5b50565b5f813590506100dc816100b8565b92915050565b5f602082840312156100f7576100f66100b4565b5b5f610104848285016100ce565b9150509291505056fea264697066735822122083bf1f648673d1110ee286ae659cc9c1299ab1d07bf83c96a591efa5df644f4864736f6c634300081a0033
0x608060405234801561000f575f80fd5b5060043610610034575f3560e01c80632e64cec1146100385780636057361d14610056575b5f80fd5b610040610072565b60405161004d919061009b565b60405180910390f35b610070600480360381019061006b91906100e2565b61007a565b005b5f8054905090565b805f8190555050565b5f819050919050565b61009581610083565b82525050565b5f6020820190506100ae5f83018461008c565b92915050565b5f80fd5b6100c181610083565b81146100cb575f80fd5b50565b5f813590506100dc816100b8565b92915050565b5f602082840312156100f7576100f66100b4565b5b5f610104848285016100ce565b9150509291505056fea264697066735822122083bf1f648673d1110ee286ae659cc9c1299ab1d07bf83c96a591efa5df644f4864736f6c634300081a0033
Creation Bytecodes: Onchain vs. Recompiled:
0x6080604052348015600e575f80fd5b506101438061001c5f395ff3fe608060405234801561000f575f80fd5b5060043610610034575f3560e01c80632e64cec1146100385780636057361d14610056575b5f80fd5b610040610072565b60405161004d919061009b565b60405180910390f35b610070600480360381019061006b91906100e2565b61007a565b005b5f8054905090565b805f8190555050565b5f819050919050565b61009581610083565b82525050565b5f6020820190506100ae5f83018461008c565b92915050565b5f80fd5b6100c181610083565b81146100cb575f80fd5b50565b5f813590506100dc816100b8565b92915050565b5f602082840312156100f7576100f66100b4565b5b5f610104848285016100ce565b9150509291505056fea264697066735822122083bf1f648673d1110ee286ae659cc9c1299ab1d07bf83c96a591efa5df644f4864736f6c634300081a0033
0x6080604052348015600e575f80fd5b506101438061001c5f395ff3fe608060405234801561000f575f80fd5b5060043610610034575f3560e01c80632e64cec1146100385780636057361d14610056575b5f80fd5b610040610072565b60405161004d919061009b565b60405180910390f35b610070600480360381019061006b91906100e2565b61007a565b005b5f8054905090565b805f8190555050565b5f819050919050565b61009581610083565b82525050565b5f6020820190506100ae5f83018461008c565b92915050565b5f80fd5b6100c181610083565b81146100cb575f80fd5b50565b5f813590506100dc816100b8565b92915050565b5f602082840312156100f7576100f66100b4565b5b5f610104848285016100ce565b9150509291505056fea264697066735822122083bf1f648673d1110ee286ae659cc9c1299ab1d07bf83c96a591efa5df644f4864736f6c634300081a0033
You'll see both the runtime and creation bytecodes match between the onchain and recompiled ones. So we say that the source-code of the contract 0x48A331150C1b442444F4f0371a4daC9Ab2FC837D on the Holesky Testnet is the one above.
But most of the times this is not as straightforward.
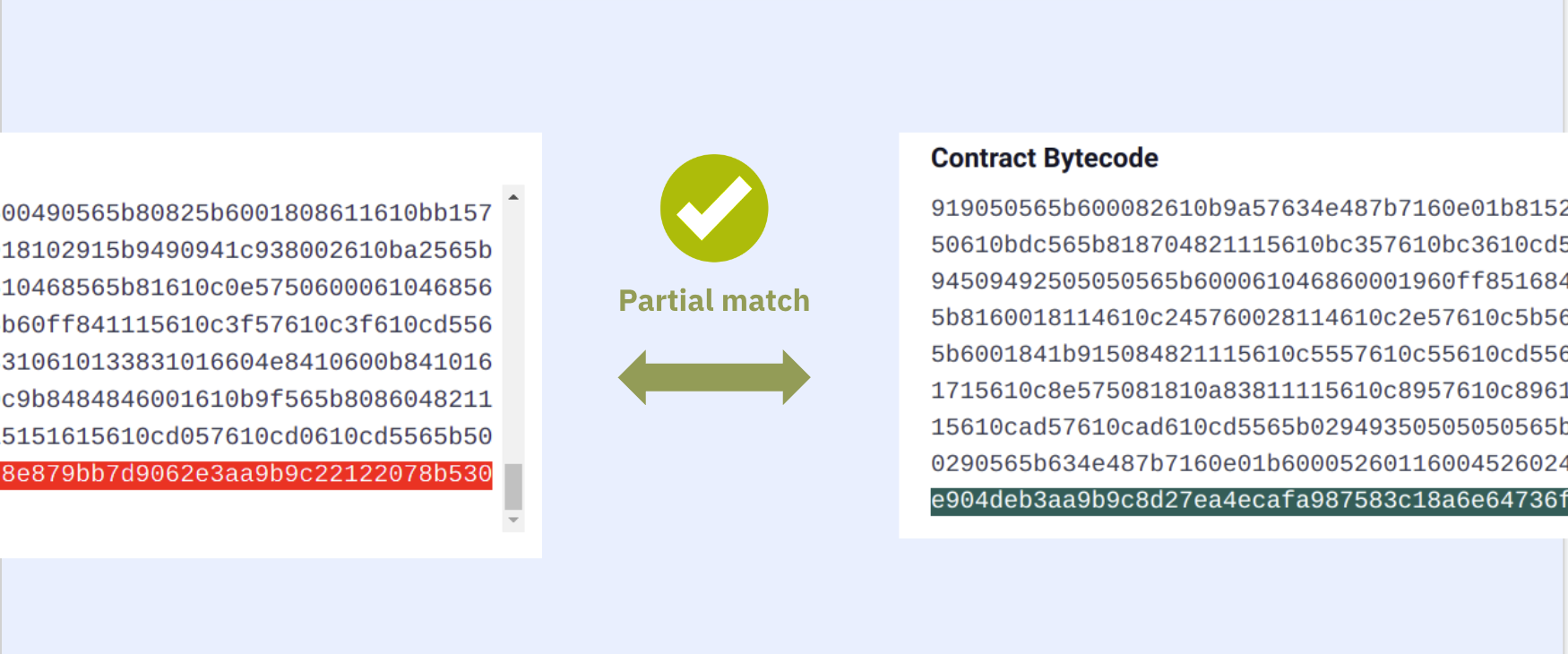
A lot of the times, parts of the bytecode are modified when the contract is being deployed. This is what we refer to as "transformations" (https://verifieralliance.org/docs/transformations) within Sourcify and the Verifier Alliance. There are certain patterns in Solidity and Vyper contracts that can change between the recompiled vs. onchain bytecodes but even with different values, the contract behaves the same. You can guess that these transformations are "data" or "metadata" of the contract embedded in its bytecode, and not the functional bytecodes i.e. opcodes.
In the Verifier Alliance's json-schemas we define the possible transformations for the creation bytecode and the runtime bytecode as such:
Creation Bytecode Transformations
There are 3 transformations possible as creation_transformations:
constructorArgumentscborAuxdatalibrary
Constructor Arguments
The constructor arguments of a contract are ABI-encoded and appended at the end of the onchain creation bytecode.
As constructor arguments are only appended to the compiled bytecode, this is an insert (append) type transformation.
Example
For a contract with constructor arguments
// SPDX-License-Identifier: GPL-3.0
pragma solidity >=0.7.0 <0.9.0;
contract Owner {
address private owner;
event OwnerSet(address indexed oldOwner, address indexed newOwner);
modifier isOwner() {
require(msg.sender == owner, "Caller is not owner");
_;
}
constructor(address passedOwner) {
owner = passedOwner; // 'msg.sender' is sender of current call, contract deployer for a constructor
emit OwnerSet(address(0), owner);
}
function changeOwner(address newOwner) public isOwner {
require(newOwner != address(0), "New owner should not be the zero address");
emit OwnerSet(owner, newOwner);
owner = newOwner;
}
function getOwner() external view returns (address) {
return owner;
}
}
The recompiled creation bytecode:
0x608060405234801561000f575f80fd5b506040516105c13803806105c18339818101604052810190610031919061014d565b805f806101000a81548173ffffffffffffffffffffffffffffffffffffffff021916908373ffffffffffffffffffffffffffffffffffffffff1602179055505f8054906101000a900473ffffffffffffffffffffffffffffffffffffffff1673ffffffffffffffffffffffffffffffffffffffff165f73ffffffffffffffffffffffffffffffffffffffff167f342827c97908e5e2f71151c08502a66d44b6f758e3ac2f1de95f02eb95f0a73560405160405180910390a350610178565b5f80fd5b5f73ffffffffffffffffffffffffffffffffffffffff82169050919050565b5f61011c826100f3565b9050919050565b61012c81610112565b8114610136575f80fd5b50565b5f8151905061014781610123565b92915050565b5f60208284031215610162576101616100ef565b5b5f61016f84828501610139565b91505092915050565b61043c806101855f395ff3fe608060405234801561000f575f80fd5b5060043610610034575f3560e01c8063893d20e814610038578063a6f9dae114610056575b5f80fd5b610040610072565b60405161004d919061028e565b60405180910390f35b610070600480360381019061006b91906102d5565b610099565b005b5f805f9054906101000a900473ffffffffffffffffffffffffffffffffffffffff16905090565b5f8054906101000a900473ffffffffffffffffffffffffffffffffffffffff1673ffffffffffffffffffffffffffffffffffffffff163373ffffffffffffffffffffffffffffffffffffffff1614610126576040517f08c379a000000000000000000000000000000000000000000000000000000000815260040161011d9061035a565b60405180910390fd5b5f73ffffffffffffffffffffffffffffffffffffffff168173ffffffffffffffffffffffffffffffffffffffff1603610194576040517f08c379a000000000000000000000000000000000000000000000000000000000815260040161018b906103e8565b60405180910390fd5b8073ffffffffffffffffffffffffffffffffffffffff165f8054906101000a900473ffffffffffffffffffffffffffffffffffffffff1673ffffffffffffffffffffffffffffffffffffffff167f342827c97908e5e2f71151c08502a66d44b6f758e3ac2f1de95f02eb95f0a73560405160405180910390a3805f806101000a81548173ffffffffffffffffffffffffffffffffffffffff021916908373ffffffffffffffffffffffffffffffffffffffff16021790555050565b5f73ffffffffffffffffffffffffffffffffffffffff82169050919050565b5f6102788261024f565b9050919050565b6102888161026e565b82525050565b5f6020820190506102a15f83018461027f565b92915050565b5f80fd5b6102b48161026e565b81146102be575f80fd5b50565b5f813590506102cf816102ab565b92915050565b5f602082840312156102ea576102e96102a7565b5b5f6102f7848285016102c1565b91505092915050565b5f82825260208201905092915050565b7f43616c6c6572206973206e6f74206f776e6572000000000000000000000000005f82015250565b5f610344601383610300565b915061034f82610310565b602082019050919050565b5f6020820190508181035f83015261037181610338565b9050919050565b7f4e6577206f776e65722073686f756c64206e6f7420626520746865207a65726f5f8201527f2061646472657373000000000000000000000000000000000000000000000000602082015250565b5f6103d2602883610300565b91506103dd82610378565b604082019050919050565b5f6020820190508181035f8301526103ff816103c6565b905091905056fea2646970667358221220f875573b100fa5b8ca92df9690b6cf74e0fa0ecbd95165b3e274ee6e68c27e9664736f6c634300081a0033
The transaction 0x0f2ab4fbc424947d36039086481ffe083d1a710df1c95a6b480ec31cf1919ebf that created the contract has the following payload:
0x608060405234801561000f575f80fd5b506040516105c13803806105c18339818101604052810190610031919061014d565b805f806101000a81548173ffffffffffffffffffffffffffffffffffffffff021916908373ffffffffffffffffffffffffffffffffffffffff1602179055505f8054906101000a900473ffffffffffffffffffffffffffffffffffffffff1673ffffffffffffffffffffffffffffffffffffffff165f73ffffffffffffffffffffffffffffffffffffffff167f342827c97908e5e2f71151c08502a66d44b6f758e3ac2f1de95f02eb95f0a73560405160405180910390a350610178565b5f80fd5b5f73ffffffffffffffffffffffffffffffffffffffff82169050919050565b5f61011c826100f3565b9050919050565b61012c81610112565b8114610136575f80fd5b50565b5f8151905061014781610123565b92915050565b5f60208284031215610162576101616100ef565b5b5f61016f84828501610139565b91505092915050565b61043c806101855f395ff3fe608060405234801561000f575f80fd5b5060043610610034575f3560e01c8063893d20e814610038578063a6f9dae114610056575b5f80fd5b610040610072565b60405161004d919061028e565b60405180910390f35b610070600480360381019061006b91906102d5565b610099565b005b5f805f9054906101000a900473ffffffffffffffffffffffffffffffffffffffff16905090565b5f8054906101000a900473ffffffffffffffffffffffffffffffffffffffff1673ffffffffffffffffffffffffffffffffffffffff163373ffffffffffffffffffffffffffffffffffffffff1614610126576040517f08c379a000000000000000000000000000000000000000000000000000000000815260040161011d9061035a565b60405180910390fd5b5f73ffffffffffffffffffffffffffffffffffffffff168173ffffffffffffffffffffffffffffffffffffffff1603610194576040517f08c379a000000000000000000000000000000000000000000000000000000000815260040161018b906103e8565b60405180910390fd5b8073ffffffffffffffffffffffffffffffffffffffff165f8054906101000a900473ffffffffffffffffffffffffffffffffffffffff1673ffffffffffffffffffffffffffffffffffffffff167f342827c97908e5e2f71151c08502a66d44b6f758e3ac2f1de95f02eb95f0a73560405160405180910390a3805f806101000a81548173ffffffffffffffffffffffffffffffffffffffff021916908373ffffffffffffffffffffffffffffffffffffffff16021790555050565b5f73ffffffffffffffffffffffffffffffffffffffff82169050919050565b5f6102788261024f565b9050919050565b6102888161026e565b82525050565b5f6020820190506102a15f83018461027f565b92915050565b5f80fd5b6102b48161026e565b81146102be575f80fd5b50565b5f813590506102cf816102ab565b92915050565b5f602082840312156102ea576102e96102a7565b5b5f6102f7848285016102c1565b91505092915050565b5f82825260208201905092915050565b7f43616c6c6572206973206e6f74206f776e6572000000000000000000000000005f82015250565b5f610344601383610300565b915061034f82610310565b602082019050919050565b5f6020820190508181035f83015261037181610338565b9050919050565b7f4e6577206f776e65722073686f756c64206e6f7420626520746865207a65726f5f8201527f2061646472657373000000000000000000000000000000000000000000000000602082015250565b5f6103d2602883610300565b91506103dd82610378565b604082019050919050565b5f6020820190508181035f8301526103ff816103c6565b905091905056fea2646970667358221220f875573b100fa5b8ca92df9690b6cf74e0fa0ecbd95165b3e274ee6e68c27e9664736f6c634300081a00330000000000000000000000002ccbc64dd59efccb5a9129b412f4ea2ef5dd1b99
Looking at the end of the contract. Recompiled creation bytecode:
...e9664736f6c634300081a0033
Transaction paylaod (onchain creation bytecode):
...e9664736f6c634300081a00330000000000000000000000002ccbc64dd59efccb5a9129b412f4ea2ef5dd1b99
You can see the following bytes are appended (insert), which is the passedOwner constructor argument in the code:
0000000000000000000000002ccbc64dd59efccb5a9129b412f4ea2ef5dd1b99
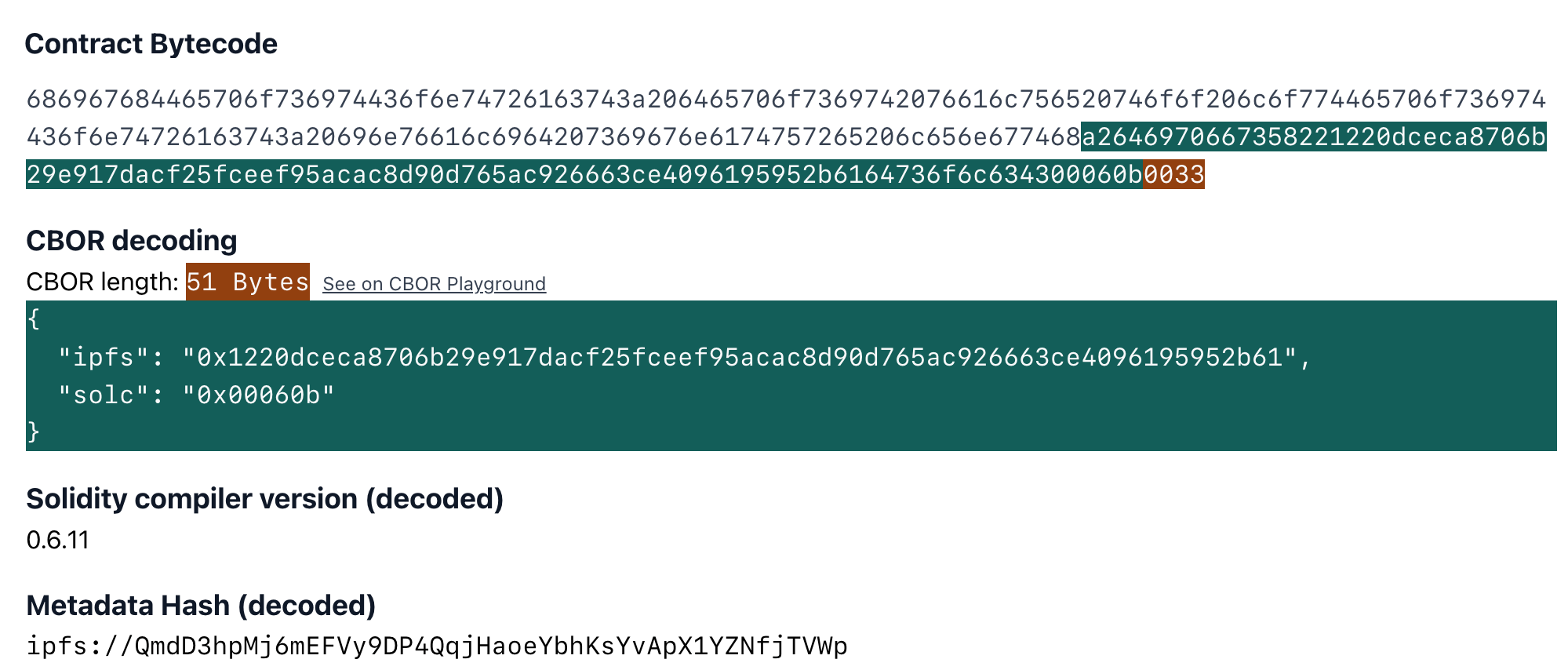
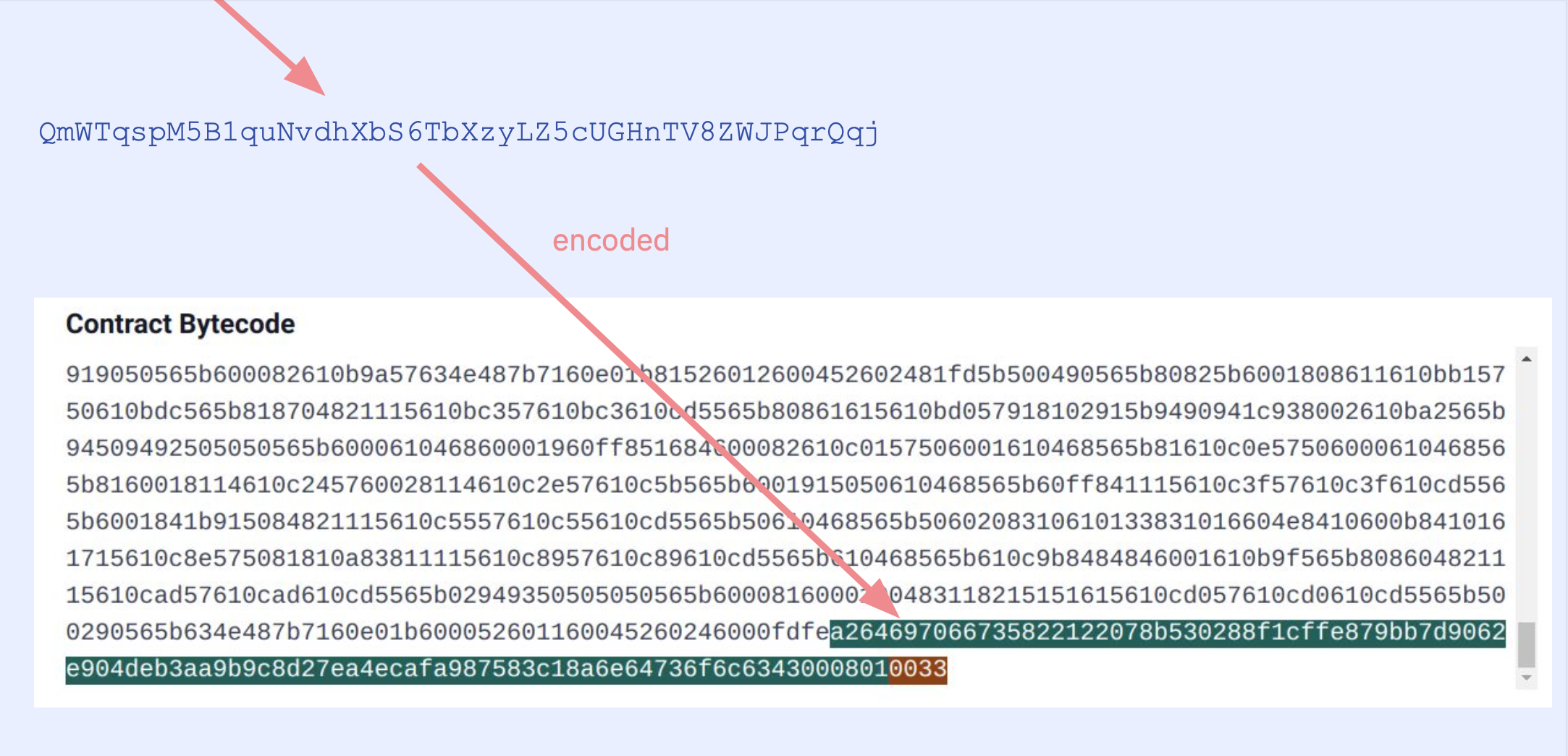
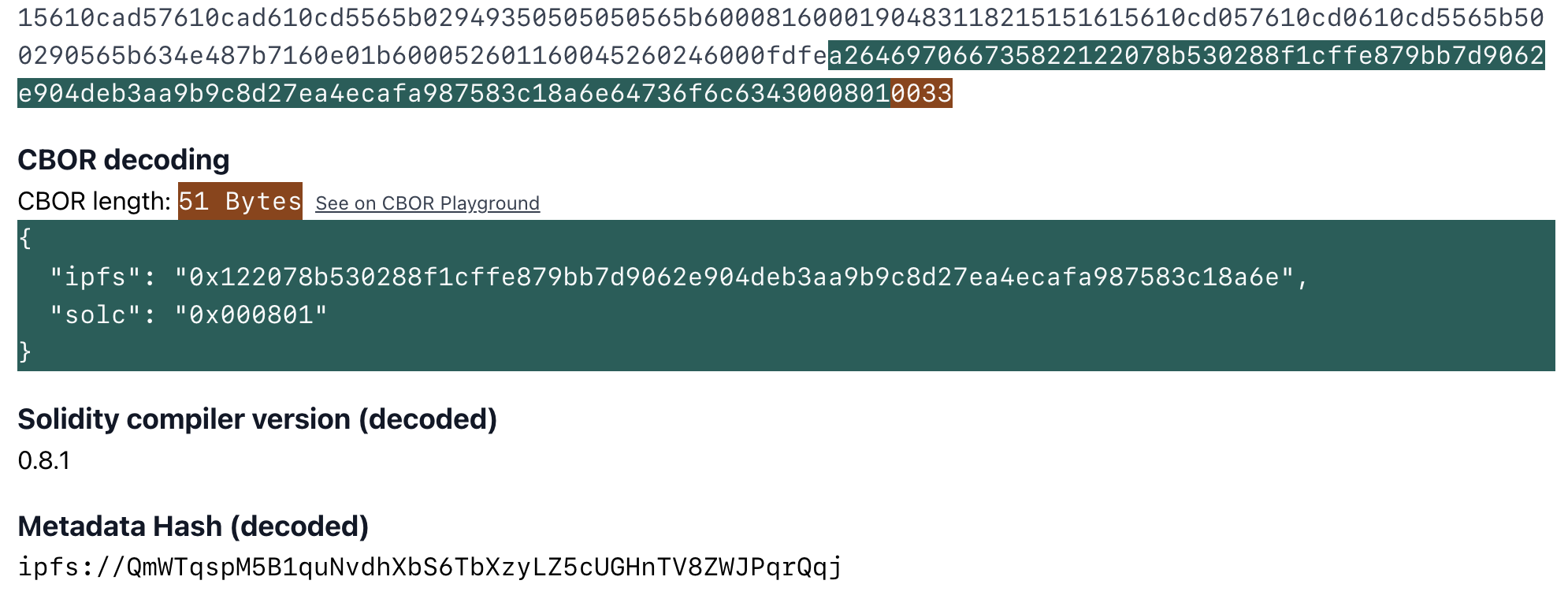
CBOR Auxdata
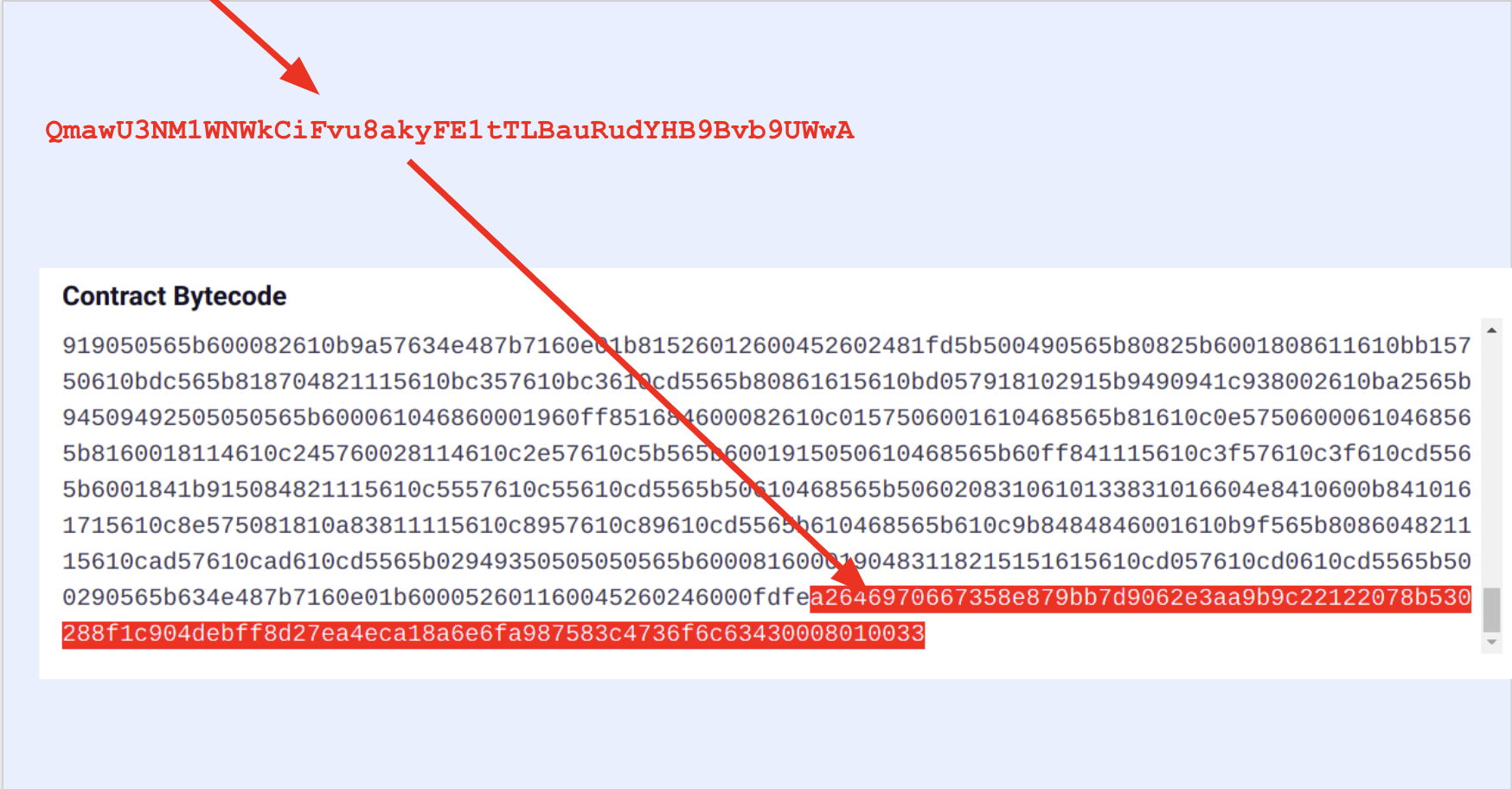
By default both the Solidity and Vyper compilers add some metadata to contract's bytecode. This is written in CBOR encoding in bytes. For Solidity contracts you can check playground.sourcify.dev
This section does not contain any opcodes or executable bytes and therefore independent from the source code we are trying to verify against. So two contracts with different cborAuxdata sections but with the rest of the bytecodes matching should match. However, Solidity and recently Vyper place an integrity hash within this cbor encoded section. If in addition to the rest of the bytecode the integrity hashes match too, this means the compilation is 100% identical with the original one, not even a whitespace or a comment in the source code is different.
However it is not straightforward to find where these sections are in the bytecode. You can read our blog post for more technical info how to do this.
To read more about how this helps with verification see our docs
Since we replace a cborAuxdata with another, this is a replace type transformation.
Example
Our previous contract 0x48A331150C1b442444F4f0371a4daC9Ab2FC837D on Holesky had the following source code:
// SPDX-License-Identifier: GPL-3.0
pragma solidity >=0.8.2 <0.9.0;
contract Storage {
uint256 number;
function store(uint256 num) public {
number = num;
}
function retrieve() public view returns (uint256){
return number;
}
}
Now if we add a comment to the source code, the functionality of the code will not change but the cborAuxdata will change because the metadata hash will be different:
contract Storage {
// This is a comment
uint256 number;
In this case the cborAuxdata parts will be different.
The onchain runtime bytecode of 0x48A331150C1b442444F4f0371a4daC9Ab2FC837D
0x608060405234801561000f575f80fd5b5060043610610034575f3560e01c80632e64cec1146100385780636057361d14610056575b5f80fd5b610040610072565b60405161004d919061009b565b60405180910390f35b610070600480360381019061006b91906100e2565b61007a565b005b5f8054905090565b805f8190555050565b5f819050919050565b61009581610083565b82525050565b5f6020820190506100ae5f83018461008c565b92915050565b5f80fd5b6100c181610083565b81146100cb575f80fd5b50565b5f813590506100dc816100b8565b92915050565b5f602082840312156100f7576100f66100b4565b5b5f610104848285016100ce565b9150509291505056fea264697066735822122083bf1f648673d1110ee286ae659cc9c1299ab1d07bf83c96a591efa5df644f4864736f6c634300081a0033
The recompiled runtime bytecode:
0x608060405234801561000f575f80fd5b5060043610610034575f3560e01c80632e64cec1146100385780636057361d14610056575b5f80fd5b610040610072565b60405161004d919061009b565b60405180910390f35b610070600480360381019061006b91906100e2565b61007a565b005b5f8054905090565b805f8190555050565b5f819050919050565b61009581610083565b82525050565b5f6020820190506100ae5f83018461008c565b92915050565b5f80fd5b6100c181610083565b81146100cb575f80fd5b50565b5f813590506100dc816100b8565b92915050565b5f602082840312156100f7576100f66100b4565b5b5f610104848285016100ce565b9150509291505056fea2646970667358221220a78868ca872a9b18cf3baa44c67d38a41d3c4e8fa71a98b42510b47c5e2a8a2764736f6c634300081a0033
You will see two cborAuxdata parts will be different:
...50509291505056fea264697066735822122083bf1f648673d1110ee286ae659cc9c1299ab1d07bf83c96a591efa5df644f4864736f6c634300081a0033
...50509291505056fea2646970667358221220a78868ca872a9b18cf3baa44c67d38a41d3c4e8fa71a98b42510b47c5e2a8a2764736f6c634300081a0033
Libraries
Libraries (in Solidity) are contracts that are deployed once to an address and can be used multiple times. If a contract is using a deployed library, the address of this library is embedded inside bytecode.
The process of passing the deployed library's address to the contract being compiled is called "library linking". Normally, this can be done by passing the libraries field to the compiler or with the --libraries flag. Otherwise the compiler will put placeholders within the bytecode where the deployed library addresses will be placed.
The placeholders look like this:
__$53aea86b7d70b31448b230b20ae141a537$__
So after a compilation, if a contract has unlinked libraries, these placeholders will be replaced with a contract address. This is also a replace type transformation.
Example
Take the following contract:
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.0;
library Lib {
function sum(uint256 a, uint256 b) external pure returns (uint256) {
return a + b;
}
}
contract A {
function sum(uint256 a, uint256 b) external pure returns (uint256) {
return Lib.sum(a, b);
}
}
Deploying this contract entails two transactions:
- Deploy the library
Libin tx 0x5bc1a60a9b2107f78d20384d1b3cf7358bc460b650d55222888ea6252429cdcb at the address 0x99F7C0086ab897C8fE65eBfF268c732a7e15b25F - Deploy the contract
Ain tx 0xc18e07649930333d7c8786c3e23ad01a6109f3cad516a01adeca90ebf12a886d at the address 0xb98c7040B589F4fEFa8690DC71Ae0FD602661F43.
If we look at the recompiled bytecodes (both runtime and creation) we can see the following section:
....0910390f35b5f73__$c6b2492631a03fef20e8d24218f6bc9947$__63cad089...
and in the onchain runtime and creation bytecodes this will be replaced with:
...0910390f35b5f7399f7c0086ab897c8fe65ebff268c732a7e15b25f63cad089...
where the difference 99f7c0086ab897c8fe65ebff268c732a7e15b25f is indeed the address of the library contract.
Keep in mind that the linked was handled by Remix manually and wasn't done through the compiler with the .libraries field. If properly linked via the compiler, there wouldn't be any placeholders. However, Remix handles both first deploying the library and manually linking the library in the contract's bytecode later for us.
Runtime Bytecode Transformations
We talked about what transformation can be done to the creation bytecodes. The transformations on runtime bytecode are similar to the creation bytecode but with two differences.
First, since constructor arguments can only exist for the creation bytecode, the runtime bytecode does not have a constructorArguments type transformation.
Second, in addition the runtime bytecode can have an immutable transformation.
The library and cborAuxdata transformations for the runtime and creation bytecodes are exactly the same.
Immutables
Immutables are contract variables that can only be set at the deploy time, cannot be changed, and embeded within the contract's bytecode itself, in contrast to other variables persisted in the contract storage.
Solidity and Vyper compilers handle immutables differently. For Vyper contracts, the immutable variables are always at the end of the runtime bytecode, so these are appened. Therefore, Vyper contracts will have an insert type transformation. In Solidity, immutables can be anywhere in the bytecode but their positions will be output within the immutableReferences field. Using this compiler output, we can apply the transformation on the recompiled runtime bytecode and see if it matches the onchain runtime bytecode.
Solidity Example
pragma solidity >=0.7.0;
contract WithImmutables {
uint256 public immutable _a;
string _name;
constructor (uint256 a) {
_a = a;
}
function sign(string memory name) public {
_name = name;
}
function read() public view returns(string memory) {
return _name;
}
}
Deployed at transaction 0x425712a9d950f7135650fd2652c528112ea7c5c5f669b843c0721a33512b9e7f with the constructor argument of value 255 (0xff in hex)
We can see the immutable both being passed as the constructor argument in the transaction payload (creation bytecode):
...e3be2f4c80faf25310b966a08079e44064736f6c634300081a003300000000000000000000000000000000000000000000000000000000000000ff
and embeded in the runtime bytecodes.
The recompiled runtime bytecode:
...059f565b5050565b7f000000000000000000000000000000000000000000000000000000000000000081565b5f8151...
The onchain runtime bytecode:
...059f565b5050565b7f00000000000000000000000000000000000000000000000000000000000000ff81565b5f8151...
Vyper Example
# pragma version ^0.4.0
OWNER: public(immutable(address))
MY_IMMUTABLE: public(immutable(uint256))
@deploy
def __init__(val: uint256):
OWNER = msg.sender
MY_IMMUTABLE = val
@external
@view
def get_my_immutable() -> uint256:
return MY_IMMUTABLE
Here we have two immutables: one being set to msg.sender and the other is passed as a constructor argument.
The contract is deployed at the transaction 0xd9b3db6bbe693a0aa8feebea814c3653014e19568e30f77722cecfed9cfd9f05.
We can see the MY_IMMUTABLE's passed value 255 (0xff in hex) in our constructor arguments appended and passed in the transaction payload (creation bytecode):
...0657283000400001400000000000000000000000000000000000000000000000000000000000000ff
And embeded (appended) to the runtime bytecodes:
Recompiled runtime bytecode (immutables will be missing):
...ffd5b5f80fd001800360054
Onchain runtime bytecode:
...ffd5b5f80fd0018003600540000000000000000000000002ccbc64dd59efccb5a9129b412f4ea2ef5dd1b9900000000000000000000000000000000000000000000000000000000000000ff
Both the OWNER and MY_IMMUTABLE are appended to the runtime bytecode.
Call Protection
Since libraries are not meant to be called with CALL instead of DELEGATECALL or CALLCODE (except view and pure functions), the Solidity compiler places a check for who's calling in the beginning of the library bytecodes. This callProtection starts with 0x73 (PUSH20) followed by the address of the contract itself and checks the current address against this.
At the deploy time, these 20 bytes will be replaced with the contract's own address.
See Solidity docs.
Example
In our previous library example we can look at the library Lib's (deployed at 0x99F7C0086ab897C8fE65eBfF268c732a7e15b25F) bytecodes. Since the call protection is not present before the deployment, i.e. in the creation bytecode, we'll only look at the runtime bytecodes:
Recompiled runtime bytecode:
0x7300000000000000000000000000000000000000003014608060405260043610610034575f3560e01c8063cad0899b14610038575b5f80fd5b610052600480360381019061004d91906100b4565b610068565b60405161005f9190610101565b60405180910390f35b5f81836100759190610147565b905092915050565b5f80fd5b5f819050919050565b61009381610081565b811461009d575f80fd5b50565b5f813590506100ae8161008a565b92915050565b5f80604083850312156100ca576100c961007d565b5b5f6100d7858286016100a0565b92505060206100e8858286016100a0565b9150509250929050565b6100fb81610081565b82525050565b5f6020820190506101145f8301846100f2565b92915050565b7f4e487b71000000000000000000000000000000000000000000000000000000005f52601160045260245ffd5b5f61015182610081565b915061015c83610081565b92508282019050808211156101745761017361011a565b5b9291505056fea26469706673582212209d56669aec61ac1867a59a6d0472bd74975630174bc6e74d7e6881bba174c30564736f6c634300081a0033
Onchain runtime bytecode:
0x7399f7c0086ab897c8fe65ebff268c732a7e15b25f3014608060405260043610610034575f3560e01c8063cad0899b14610038575b5f80fd5b610052600480360381019061004d91906100b4565b610068565b60405161005f9190610101565b60405180910390f35b5f81836100759190610147565b905092915050565b5f80fd5b5f819050919050565b61009381610081565b811461009d575f80fd5b50565b5f813590506100ae8161008a565b92915050565b5f80604083850312156100ca576100c961007d565b5b5f6100d7858286016100a0565b92505060206100e8858286016100a0565b9150509250929050565b6100fb81610081565b82525050565b5f6020820190506101145f8301846100f2565b92915050565b7f4e487b71000000000000000000000000000000000000000000000000000000005f52601160045260245ffd5b5f61015182610081565b915061015c83610081565b92508282019050808211156101745761017361011a565b5b9291505056fea26469706673582212209d56669aec61ac1867a59a6d0472bd74975630174bc6e74d7e6881bba174c30564736f6c634300081a0033
After matching
If we got a match, it means that the provided source code and metadata can be associated with the contract at this chainId and address and we mark this contract as verified. It also means we can start from recompiled bytecodes, apply each runtime or creation transformations on top of the respective recompiled bytecodes, and obtain the onchain bytecodes.
Finally, we store our contract in our storage backend of choice. Currently this can be a file system or a SQL database in Sourcify's case. By default we do both. See the Contract Repository docs for more information.
EOF and the road ahead
Big changes to how the EVM bytecode is structured is coming up with the EVM Object Format proposal. According to how the compilers implement these changes, the verification process face changes and verifying pre-EOF contracts will be different than the EOF contracts.
One nice feature of the EOF is it separates code from data and gives structure to code. This makes us verifiers' lives much easier compared to the completely unstructured legacy EVM code. The legacy EVM example can be seen in our post Finding Auxdatas in the Bytecode. However as of the current specification, the metadata is still not fully isolated from the contract code as there is no separate section for that information. Current compiler implementations put the metadata in the data_section of EOF and this unfortunately does affect the contract's code. That's why we are proposing a separate metadata_section in the EVM Object Format that cannot be reached by the EVM and any changes to that will not affect the contract's code. If this is implemented, verifiers can completely ignore the metadata parts of a container, and won't have to look for workarounds.
You can check our proposal EIP-7834