In the earlier days of Sourcify, there were other things we were focusing on besides source-code verification. Sourcify was there to foster the adoption of the Solidity metadata and to make transactions human-readable.
Since September 2021, I've been the only one working on the project until Marco joined in July 2022 and Manuel in April 2024. You will see in our earlier talks we start with the problem statement of "YOLO signing" and explain how Sourcify, Solidity metadata.json, and NatSpec can solve this. That talk is actually my first ever conference talk (can be seen from how nervous I am), and I was naive. The idea was that if you document your Solidity methods with NatSpec, this userdoc/devdoc will be in the metadata.json and you can use these human-readable messages to tell the user what is going to happen before calling this contract method (more below).
The old Sourcify website highlighting human-readable transactions as a key feature
Getting more familiar with the problem, soon I realized this huge problem can't be solved with metadata.json + NatSpec only. We had to attack the problem from different angles for different cases. This led us to start the initiative "Human-Readable Transactions Working Group" (kudos to Dustin and Karen for the help) with actually many people ranging from Safe, Metamask, Coinbase Wallet etc. We held multiple calls but unfortunately we as Sourcify couldn't continue our coordinating role and the initiative died around August 2023. Marco and I didn't have enough bandwidth and experience, and had to go back to focusing on our core value proposition of making source-code verification open-source and the verified contract data open and accessible.
The problem of blind-signing turned out to be a bigger dragon than we can slay.
Still we learned a lot and I got to see what people have been proposing to solve this. Following the ByBit hack that was essentially caused by blind-signing, I'll take this chance to gather everything we've learned here and share with everyone. There have been countless cases of people losing significant amounts of money because of blind signing. But the ByBit hack, the biggest hack ever in crypto history, with 1.4 billion USD stolen, has brought the attention back to this issue.
I started this article with blind-signing in mind but the problem is actually even larger: it's transaction safety. It means nothing if you can read a transaction but it does not do what you read or if you're talking to the wrong contract. It's layers and layers and layers of security. Which also means layers and layers and layers of coordination effort. That's why it's so difficult.
By no means this is a complete guide. I'm more than happy to extend this. Please get in touch if you have anything to add!
1. Source Code Verification
This is a MUST. Period. Without verification there's no way to tell what a contract really does.
DO NOT INTERACT WITH CONTRACTS THAT ARE UNVERIFIED
The contract should be verified by a verifier, but ideally it is verified at multiple places. Even better if the verification is a "perfect/exact match", this gives you a cryptographic guarantee that what you see is exactly what the contract author deployed, even the comments, whitespaces etc.
Players here: Blockscout, Etherscan, Routescan, Tenderly, Sourcify, and the Verified Alliance initiative.
Wallets MUST warn users about unverified contracts and use multiple sources to check verification. Unfortunately, even in 2025, not many do even this simple requirement.
The tricky thing here is to not lead the user to believe verified == safe. A verified contract can still be malicious and verification does not check what the contract does. I actually wish we had a better name like "open-sourced contracts" instead of verification, but it is what it is.
2. Labeling
The second step is to make sure you are talking to the correct contract. You think you are making a swap on Uniswap but is it really Uniswap or just a verified Uniswap copy at another address? Maybe the contract you are talking to is already marked malicious and it'd be such a shame to lose money to an already known scammer.
So this entails whitelists and blacklists of contracts. I don't have deep knowledge around this but I don't really recall seeing contract labels in my wallets. There are "web3 security" companies or Etherscan labels but the problem with these is everyone solves it for themselves.
I'll be saying this many times:
In order to solve this problem once and for all, THE SOLUTION HAS TO BE OPEN.
Closed, siloed data will only get us so far.
Here the project I want to highlight is the Open Labels Initiative stewarded by growthepie.xyz. If there are other solutions/projects worth sharing, please share them.
3. Audits
This is part of labeling but it deserves its own mentioning. We need open, public audit lists of contracts. Wallets need to show if the contract you are about to interact with is audited and if not warn you against this.
The second step could be to create a ranking/reputation system of auditors, as you all know, not all auditors are created equal. And again, all these lists MUST be open and public. Note that I don't mean "decentralized" necessarily. A good enough centralized solution is better than nothing as long as the data is fully open, not monetized, and incentives are aligned to keep it that way. This can be an alliance of multiple parties, or a project sustained by grants. As you can see, this by itself is already a big enough problem to solve.
This is also not a part of the ecosystem I'm not too knowledgeable in so please share what you know.
4. Human-Understandability of Transactions
I named this "understandability" instead of "readability" because readability is just a necessary but non-sufficient part of our main goal i.e., being able to understand what you are doing. Reading swapTokensForExactTokens is quite a meaningless word for a normal person, even though readable. If you have no idea what you're doing, you're basically giving out your money.

Dog-readable transactions, anyone?
4.1 ABI-Decoding
It's year 2025 and I can't believe I have to mention this.
By now it should be trivial to take the ABI JSON of a contract (verification required), and decode the calldata.
Most of the time this is not really helpful to the user though.
Tx 0x5a45979e2a4a22855a1a2aee1ecb346b4ecee2d4e498817e8ed98d86476809ce on Mainnet
If you're given only the raw calldata:
0xe56461ad000000000000000000000000000000000000000000000000000000000000a86a000000000000000000000000ad26509077edd15f7cc9bf04cc58891c8f51a75d
A really simple decoding yields a much more meaningful message (decoded in Blockscout):
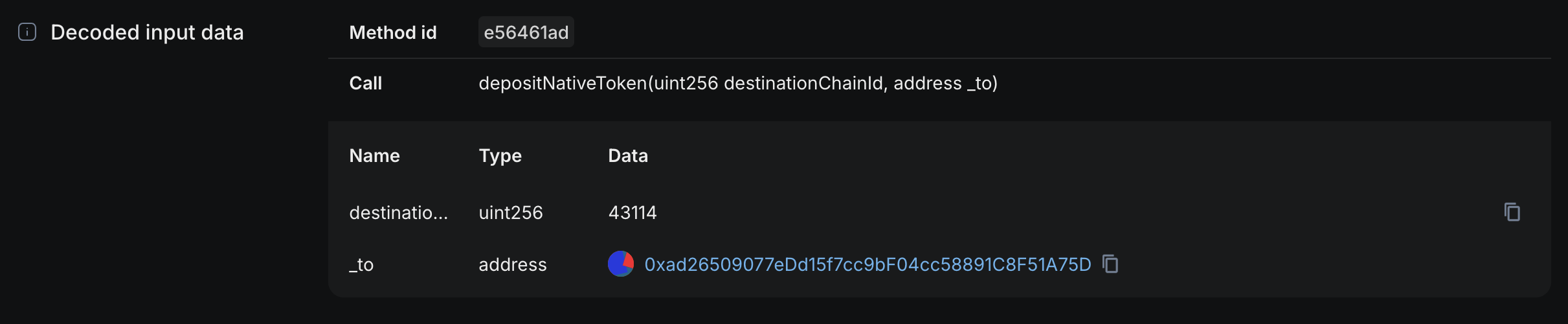
This is incredibly straightforward, just pull the ABI from a verifier, and decode with a framework like in ethers.js: abiCoder.decode(abiParamInputs, calldata). It's really sad even this is lacking in a lot of the places.
ABI-decoding is not always this helpful though. Usually the called methods have a lot more complex arguments and not as simple as the one above.
This category refers to leveraging function metadata, apart from the function itself (e.g. ABI) to provide more information about it.
ABI-Decoding + NatSpec
There's additional human-readable information found in well written Solidity contracts in the form of NatSpec, a commenting syntax.
NatSpec has @notice and @dev fields that are intended to explain the "user" and the "developer" respectively what this method does, as well as the @param method to document the "parameters".
Example from my talk at the BlockSplit 2022 conference (link to slides):
function swapOwner(
address prevOwner,
address oldOwner,
address newOwner
) public authorized {...
So that a user can see a more human-readable message about the method they are calling:
userdoc: Replaces the owner `oldOwner` in the Safe with `newOwner`
devdoc: Allows to swap/replace an owner from the Safe with another address. This can only be done via a Safe transaction.
function: swapOwner(address prevOwner, address oldOwner, address newOwner)
- prevOwner:
- documentation: Owner that pointed to the owner to be replaced in the linked list
- value: 0x1F98431c8aD98523631AE4a59f267346ea31F984
- oldOwner:
- documentation: Owner address to be replaced.
- value: 0xcC60F45e0507032036033b361d3a6457b9F0283D
- newOwner:
- documentation: New owner address.
- value: 0x83D0360050703233b361d3a6457b9F2cC60F45e0
Additionally NatSpec also suggests using "dynamic expressions" to put variable names in backticks like `oldOwner` for the consumers of the spec to dynamically fill the values. With that a user calling this function can see a much more human readable message:
userdoc: Replaces the owner 0xcC60F45e0507032036033b361d3a6457b9F0283D in the Safe with 0x83D0360050703233b361d3a6457b9F2cC60F45e0
Note that these meaningful messages all assume you are talking to a benign and secure contract. A malicious contract can still have nice human readable NatSpec docs while doing a completely different thing than what it says. All points mentioned above like verification, labeling etc. are requirements for this to make any sense.
NatSpec documentation can be obtained by requesting userdoc and devdoc under outputSelection in compilers settings. Additionally it's found under Solidity contract metadata.json. The hash of this file is appended at the end of the contract and provides extra cryptographic guarantees about the verification. No other verifier leverages or provides this output except Sourcify (obtainable via APIv2). Also see playground.sourcify.dev to learn more.
We forked the aragon/radspec repo and played around with it as a Metamask Snap but didn't pursue this further for reasons mentioned in the beginning.
As said, NatSpec also falls short in many cases. First of all, it's not backwards compatible. We can't inject NatSpec to already deployed contracts. It's also not always sufficient to make sense of complex transactions. Here's a Uniswap call that actually isn't complex:
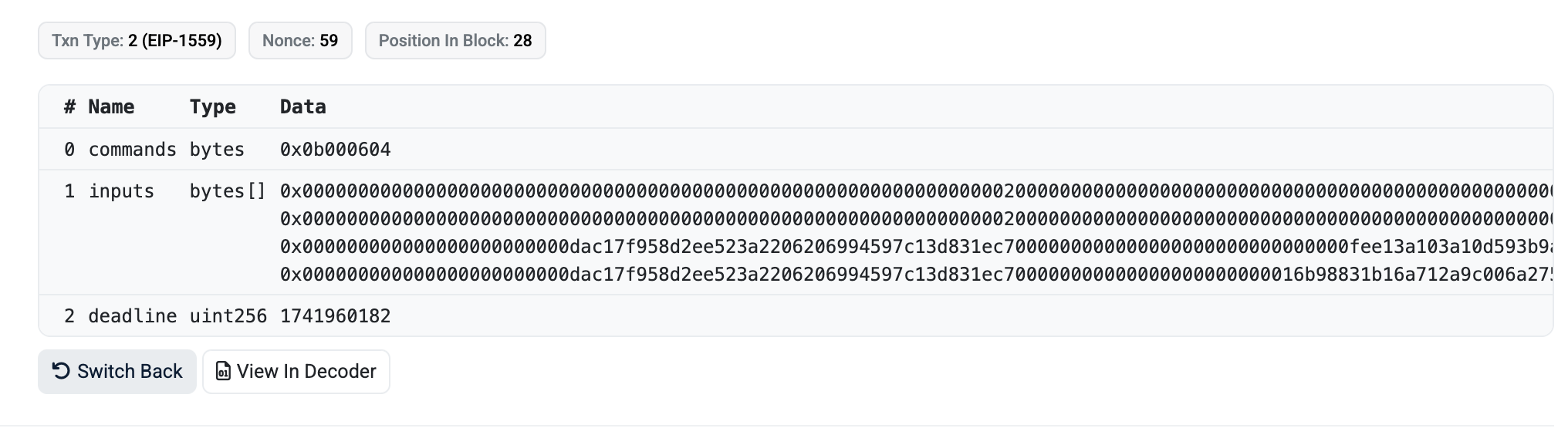
commands? inputs? no idea what's going on. Looking at the NatSpec helps a little:
function execute(bytes calldata commands, bytes[] calldata inputs, uint256 deadline) external payable;
At least now we know what the parameters mean but still we would have to look at the Commands implementation in the contract to make sense of it. NatSpec gets us so far.
ERC-4430: Described Transactions
This was an old EIP from @ricmoo and @arachnid to place the human-readable descriptions of functions in the contract itself.
The high-level idea is to have a "describer" function within the contract itself. Wallets etc. would call that describer to show the user a message before sending a tx.
As in the spec:
In many cases, the information that would be necessary for a meaningful description is not present in the final encoded transaction data or message data.
For example, the commit(bytes32) method of ENS places a commitment hash on-chain. The hash contains the blinded name and address; since the name is blinded, the encoded data (i.e. the hash) no longer contains the original values and is insufficient to access the necessary values to be included in a description.
By instead describing the commitment indirectly (with the original information intact: NAME, ADDRESS and SECRET) a meaningful description can be computed (e.g. "commit to NAME for ADDRESS (with SECRET)") and the matching data can be computed (i.e. commit(hash(name, owner, secret))).
The spec proposes an additional contract method such as:
function eip4430Describe(bytes inputs, bytes32 reserved) view returns (string description, bytes execcode)
Instead of calling transfer() directly, you'd call this function which would return your wallet a human-readable description and the execcode the wallet can execute in a subsequent transaction if the description is "accepted".
This is a more "onchain" solution that requires defining these descriptions inside the contract. But also because of that it's not backwards compatible for existing contracts.
Also related for signatures ERC-3224: Described Data
This was proposed by @danfinlay in Ethereum Magicians Forum but didn't proceed to an EIP.
My understanding of this proposal is that the first point of contact of the wallet to the contract (e.g. dapp the website) provides human-readable metadata to be saved in the wallet. From then on, the wallet always shows human-readable information to the user in the wallet.
This would be backwards compatible for existing contracts.
I like this proposal's approach to provide this information to the user in the first point of contact ever with the dApp. The website would be responsible for passing this information and in a kind of secure way if provided with HTTPS.
Function/Event Templating and ERC-7730
Similar to above proposal, we can generate a "function templates registry" that will map a chainId+address+function to a string template that can be dynamically filled and human-readable. While the above, from my understanding is more decentralized, that every dApp provides its own messages, here it's a centralized registry possibly with a template language.
E.g. the function or event on a specific contract
borrowAsset(uint256 _borrowAmount,uint256 _collateralAmount,address _receiver)
BorrowAsset (index_topic_1 address _borrower, index_topic_2 address _receiver, uint256 _borrowAmount, uint256 _sharesAdded)
can become "Borrowed {tokenAmount} {tokenName} on {dAppName}".
I guess a lot of the explorers, portfolio managing apps, wallets do this for popular contracts and functions. The problem again here is everyone's trying to solve it for themselves. There's no coordinated effort that I'm aware of that is open and solves this once and for all! (Edit: See below) Except maybe rotki because it's purely open-source but I don't know their registry or DB for this.
IMO it's fine that this is centralized initially and held in a place even like Github to begin with. Eventually there will be the problem of "who" provides these messages and if they are trusted parties. E.g. what if an attacker is able to inject a misleading message? Or is it going to be permissionless that attackers can also provide human-readable messages for their own malicious contracts. One can start small here with a trusted set of participants and expand slowly.
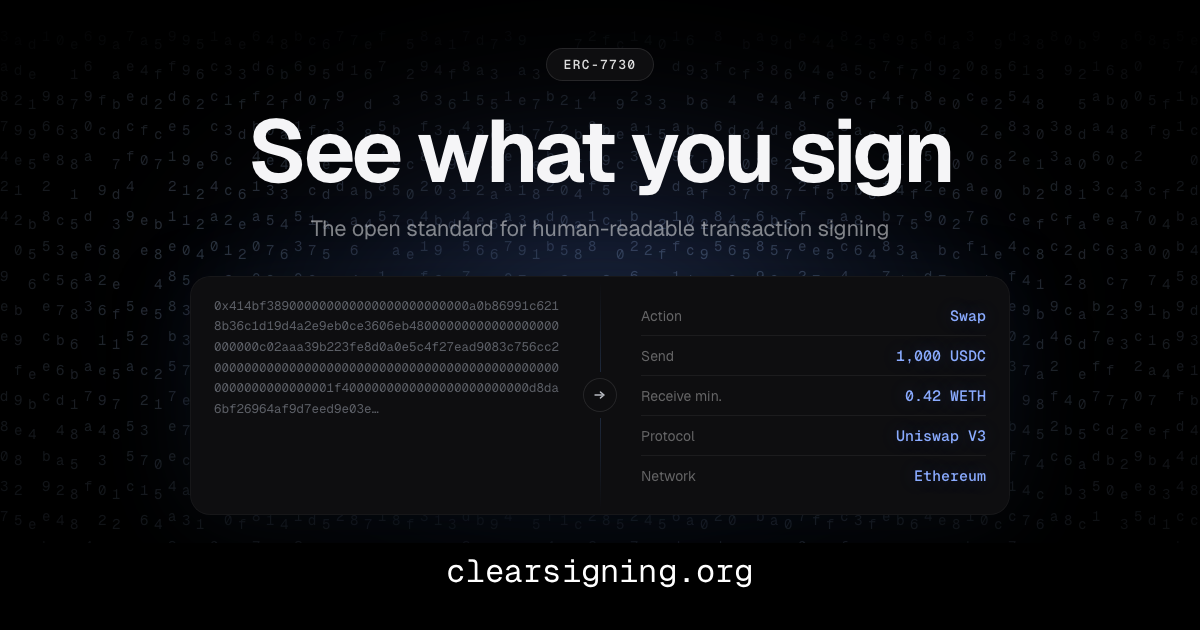
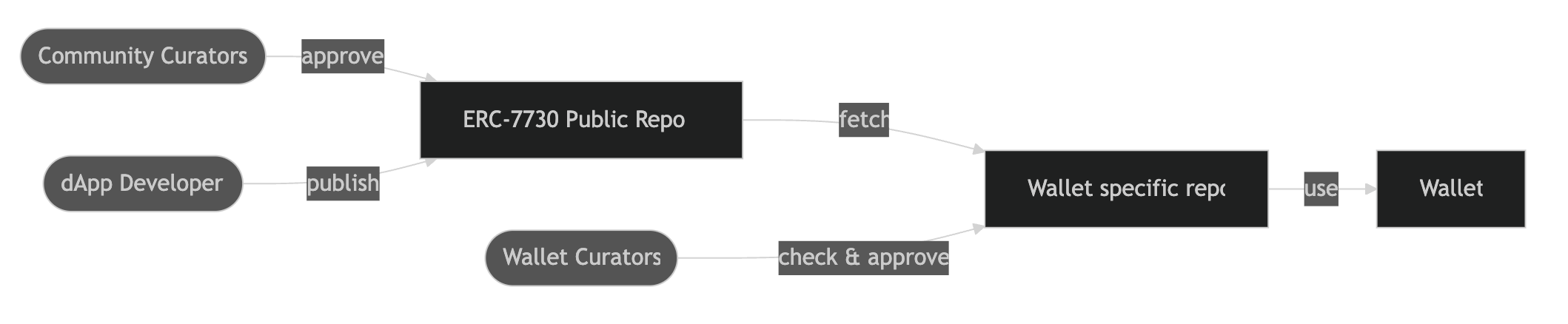
ERC-7730 (by Ledger)
Turns out ERC-7730 is exactly what I describe above (see full EIP). The spec proposes a JSON schema to provide human readable messages and annotate function parameters to format them nicely.
Example from a Lido contract:
"display": {
"formats": {
"wrap(uint256)": {
"intent": "Exchange stETH to wstETH",
"fields": [
{
"path": "_stETHAmount",
"label": "Amount to exchange",
"format": "tokenAmount",
"params": { "token": "$.metadata.constants.stETHaddress" }
}
]
},
When the user calls wrap(10000000000000000000) they will be shown:
Review transaction to: Exchange stETH to wstETH
Amount to exchange: 1 stETH
From what I understand this also supports nested calls or multicalls if this is specified properly.
The whole submission to wallet workflow is depicted nicely in this diagram from the spec:
The biggest con I see with this initiative is it's branded everywhere as "by Ledger". Kudos to Ledger for coming up with this as an open spec but as long as this remains under Ledger's ownership in their repos, there's no incentive for other wallets to adopt this standard. Such an initiative should be led by a neutral entity or a consortium, and really not be marketed with the wallet's name everywhere. This is already mentioned in the original EIP:
- Foundation operated repository, like ethereum chainID list: good alternative between decentralization and discoverability.
- Ledger repository: as a short term solution, Ledger is providing a central repository (See Ledger GitHub repository)
To me this is the biggest drawback of this intiative and Ledger should stop marketing this through themselves if they really want this to succeed.
4.3 Transaction Simulation
This is one field that good progress was made. A lot of services provide tools or APIs to simulate the steps and outcomes of a transaction and it's somewhat well integrated into wallets.
A lot of services provide Transaction Simulation through their APIs and it should be easy to hook. Here are some I'm aware of:
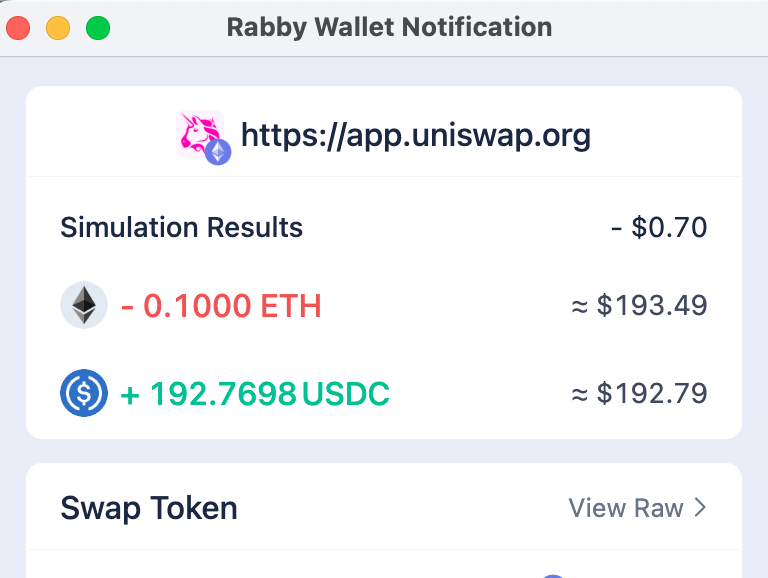
Rabby Wallet does a great job here to show the simulation results to the user:
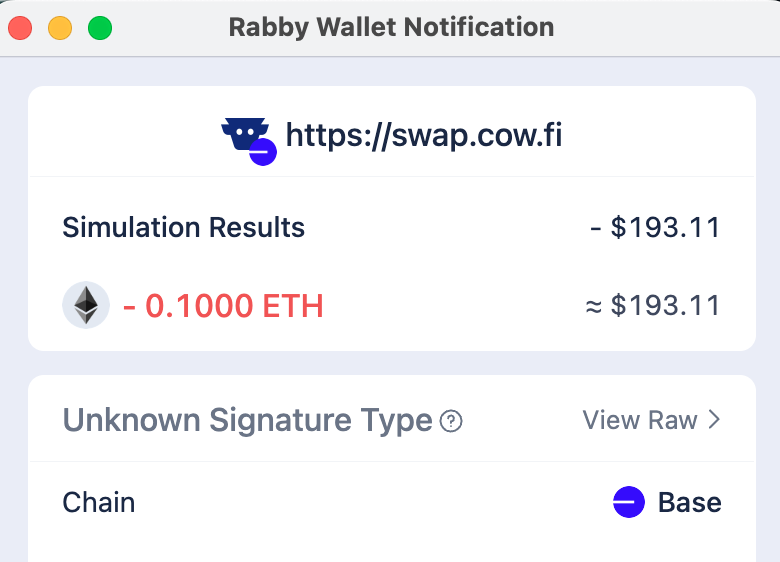
But also as a reminder this is not a silver bullet again. For example it isn't able to find out what I'll receive from the CoWSwap swap, likely because how CoWSwap works with solving auctions etc:
5. Browser Wallet to Hardware Wallet Integrity
Even if we did everything above perfectly, we wouldn't be able to prevent the ByBit attack because what the signers were seeing on their machines were benign but they were actually signing a malicious transaction. Of course they should've checked what they were signing on their hardware wallets but this is obviously not working. A lot of the users slack, don't want to read hexadecimals (understandably) and just accept what's provided.
I think there's a lot of room for improvement in the SW to HW wallet integrity field and a lot of low-hanging fruits.
One example I thought about in this tweet is using emojis to do integrity checks instead of hexadecimals.
8 emojis = 32 bytes, we could hash the tx content—if anything changes, the emojis shift completely.
- Browser: 😒🙏👰👨🦼🦷👳♂️👷♀️🧓
- HW Wallet: 😒🙏👰👨🦼🦷👳♂️👷♀️🧓
✅ Pass
- Browser: 😒🙏👰👨🦼🦷👳♂️👷♀️🧓
- HW Wallet: 😁☺️😾🤲🙎♂️☂️🩰🩳
❌ Fail
HW Wallet limitations
One thing to keep in mind is that a large portion on the hardware wallets are limited in their resources as well as their displays. There is so much information we can put in it. Newer wallets have larger and more information rich displays but they are also expensive. An ideal solution should cover cheaper alternatives too even if not fully backwards compatible to the exiting lower-grade hardware wallets.
Conclusion
The journey to solve blind signing has taught us some valuable lessons about the complexity of the problem and I wanted to share what we have found here. As you can see "transaction safety" is not just clear-signing and it's layers and layers of security and coordination. The clear-signing part also has had multiple attempts to solve and none is perfect. Still the main issue is none of the proposals is on production (except simulation) and they all remained as wishful specs. Having something is better than having nothing.
While we started with the goal of making transactions more human-readable, we discovered that this challenge requires a coordinated effort across the entire ecosystem. I am hoping the ByBit hack serves as a wake-up call to the entire ecosystem and we start working on this intentionally. As Sourcify we have more bandwidth compared to back than and will be willing to support the coordination efforts.
If you liked this, please share and spread the word and we can start some open discussion. If you have feedback or other ideas, also let me know on X! @kaanuzdogan